Lecture 1 Small data
The stream processing technology is becoming more and more popular with big and small companies because it provides superior solutions for many established use cases such as data analytics, ETL, transactional apps, software architectures, and business opportunities. We try to describe why stateful stream processing is becoming so popular and assess its potential.
But first, we start by reviewing classical data app architectures and point out their limitations.
Data. From data file to data lake
The development of information technology has resulted in access to unimaginable amounts of a new resources which are structured and unstructured data.
Data has contributed to the development of thousands of new tools for generating, collecting, storing and processing information on an unprecedented scale.

The emergence of new scientific or business challenges becomes possible thanks to the construction of systems based on open software, and the use of home computers to support the processing of huge amounts of data.
The new kind of business and scientific challenges include:
- intelligent advertising of thousands of products for millions of customers,
- processing of data about genes, RNA or proteins genus,
- intelligent detection of various methods of fraud among hundreds of billions of credit card transactions,
- stock market simulations based on thousands of financial instruments,
- … The data age presents us with newer and newer challenges related not only to the quantity but also to the time of data processing.
All machine learning algorithms require structured data written in a tabular form. They are organized in columns of characteristics that characterize each observation (rows). An example may be such features as sex, growth or the number of owned cars, of which it can be predicted whether the customer will repay the loan or not. This prediction is also collected as a feature. Thanks to the tables of features obtained in this way, we can use XGBoost or logistic regression algorithms to determine the appropriate combination of variables affecting the probability of a good or bad customer.
Unstructured data is data that is not arranged in a tabular form. Examples include sound, images and text. In the process of processing, they are always converted into some vector form. However, individual letters, frequencies or pixels do not convey any information. They do not create separate features, which is crucial to distinguish them from structured data.
Give an example of structured and unstructured data. Load sample data in jupyter notebook.
Knows the types of structured and unstructured data (K2A_W02, K2A_W04, O2_W04, O2_W07)
Data sources
The three largest data generators are:
- social data in the form of texts (tweets, entries in social networks, comments), photos or videos. These data are very important due to their wide possibilities of consumer behaviour and sentiment analysis in marketing analyses.
- data from all kinds of sensors or logs of the operation of devices and users (e.g. on a website). These data are related to IoT (Internet of Things) technology, which is currently one of the most developing areas in data processing, but also in the business direction.
- Transaction data, which is generally what is always generated as transactions appearing both online and offline. Currently, this type of data is processed for the purpose of performing transactions and rich analytics supporting virtually every area of everyday life.
Actual data generation process
The data that is in reality appears as a result of the continuous operation of the systems. You have generated a lot of data on your phone today (and even on these devices!) Will it not generate them early or tomorrow? Batch processing splits the data into a time-length chunk and runs granular processes at a user-specified time . However, the timestamp is not always appropriate.
With many systems that handle the data streams that you already have. They are e.g.: - data warehouses - devices monitoring systems (IoT) - transaction systems - website analytics systems - Internet advertising - social media - operating systems - ….
a company is an organization that works and responds to a constant stream of data.
The input to the orchard source (but also the result of the evaluation) of the data is the file. It is written once and can be referred to (multiple functions - tasks can run on it). The name of the file to identify the record set.
In the case of the stream of change, it is only once through the so-called manufacturer (also referred to as the sender or supplier). They can be formed by many so-called consumers (recipients). Streaming events are grouped into so-called topic (eng. topic).
not to Big Data
,,Big Data is like teenage sex: everyone talks about it, nobody really knows how to do it, everyone thinks everyone else is doing it, so every one claims they are doing it.’’ — Dan Ariely, Professor of Psychology and Behavioral Economics, Duke University
one, two, … four V
- Volume - the size of the data produced worldwide is growing exponentially. Huge amounts of data are being generated every second - the email you send, Twitter, Facebook, or other social media, videos, pictures, SMS messages, call records and data from varied devices and sensors.
- Velocity - the speed of data production, the speed of their transfer and processing.
- Variety - we associate traditional data with an alphanumeric form composed of letters and numbers. Currently, we have images, sounds, videos and IoT data streams at our disposal
- Veracity - Is the data complete and correct? Do they objectively reflect reality? Are they the basis for making decisions?
- Value - The value that the data holds. In the end, it’s all about cost and benefits.
The purpose of calculations is not numbers, but understanding them R.W. Hamming 1962.
As You can see data and data processing have been omnipresent in businesses for many decades. Over the years the collection and usage of data have grown consistently, and companies have designed and built infrastructures to manage that data.
Data processing models
The traditional architecture that most businesses implement distinguishes two types of data processing.
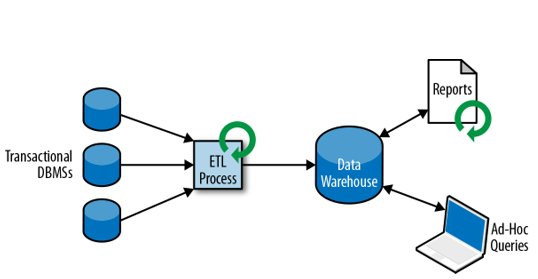
Most of the data is stored in databases or data warehouses. By default, access to data comes down to the implementation of queries via applications. The method of using and implementing the database access process is called the processing model. Two implementations are most commonly used:
Traditional Model
Traditional model - on-line transaction processing, OLTP (on-line transaction processing). It works great in the case of ongoing service, e.g. customer service, order register, sales service, etc. Companies use all kinds of applications for their day-to-day business activities, such as Enterprise Resource Planning (ERP) Systems, Customer Relationship Management (CRM) software, and web-based applications. These systems are typically designed with separate tiers for data processing and data storage (transactional database system).
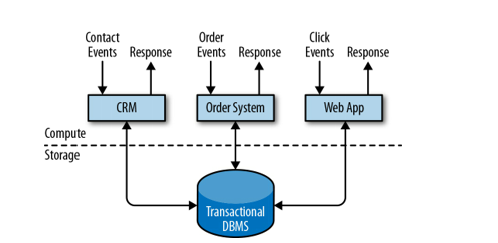
Applications are usually connected to external services or face human users and continuously process incoming events such as orders, emails, or clicks on a website.
When an event is processed, an application reads its state or updates it by running transactions against the remote database system. Often, a database system serves multiple applications that sometimes access the same databases or tables.
This model provides effective solutions for:
- effective and safe data storage,
- transactional data recovery after a failure,
- data access optimization,
- concurrency management,
- event processing -> read -> write
And what if we are dealing with:
- aggregation of data from many systems (e.g. for many stores),
- supporting data analysis,
- data reporting and summaries,
- optimization of complex queries,
- supporting business decisions.
Research on such issues has led to the formulation of a new data processing model and a new type of database (Data warehouse).
This application design can cause problems when applications need to evolve or scale. Since multiple applications might work on the same data representation or share the same infrastructure, changing the schema of a table or scaling a database system requires careful planning and a lot of effort. Currently, many running applications (even in one area) are implemented as microservices, i.e. small and independent applications (LINUX programming philosophy - do little but right). Because microservices are strictly decoupled from each other and only communicate over well-defined interfaces, each microservice can be implemented with a different technology stack including a programming language, libraries and data stores.
This model provides effective solutions for:
- effective and safe data storage,
- transactional data recovery after a failure,
- data access optimization,
- concurrency management,
- event processing -> read -> write
And what if we are dealing with:
- aggregation of data from many systems (e.g. for many stores),
- supporting data analysis,
- data reporting and summaries,
- optimization of complex queries,
- supporting business decisions.
Research on such issues has led to the formulation of a new data processing model and a new type of database (Data warehouse).
This application design can cause problems when applications need to evolve or scale. Since multiple applications might work on the same data representation or share the same infrastructure, changing the schema of a table or scaling a database system requires careful planning and a lot of effort. Currently, many running applications (even in one area) are implemented as microservices, i.e. small and independent applications (LINUX programming philosophy - do little but right). Because microservices are strictly decoupled from each other and only communicate over well-defined interfaces, each microservice can be implemented with a different technology stack including a programming language, libraries and data stores.
Both are performed in batch mode. Today they are strictly made using Hadoop technology.