from pyspark import SparkContextApache Spark intro
Apache Spark is a general-purpose, in-memory computing engine. Spark can be used with Hadoop, Yarn and other Big Data components to harness the power of Spark and improve the performance of your applications. It provides high-level APIs in Scala, Java, Python, R, and SQL.
Spark Architecture
Apache Spark works in a master-slave architecture where the master is called “Driver” and slaves are called “Workers”. The starting point of your Spark application is sc, a Spark Context Class instance. It runs inside the driver.


Apache Spark: Sometimes also called Spark Core. The Spark Core implementation is a RDD (Resilient Distributed Dataset) which is a collection of distributed data across different nodes of the cluster that are processed in parallel.
Spark SQL: The implementation here is DataFrame, which is a relational representation of the data. It provides functions with SQL like capabilities. Also, we can write SQL like queries for our data analysis.
Spark Streaming: The implementation provided by this library is D-stream, also called Discretized Stream. This library provides capabilities to process/transform data in near real-time.
MLlib: This is a Machine Learning library with commonly used algorithms including collaborative filtering, classification, clustering, and regression.
GraphX: This library helps us to process Graphs, solving various problems (like Page Rank, Connected Components, etc) using Graph Theory.
Let’s dig a little deeper into Apache Spark (Spark Core), starting with RDD.
sc = SparkContext(appName="myAppName")scRDD
- Resilient Distributed Dataset
- Podstawowa abstrakcja oraz rdzeń Sparka
- Obsługiwane przez dwa rodzaje operacji:
- Akcje:
- operacje uruchamiająceegzekucję transformacji na RDD
- przyjmują RDD jako input i zwracają wynik NIE będący RDD
- Transformacje:
- leniwe operacje
- przyjmują RDD i zwracają RDD
- Akcje:
- In-Memory - dane RDD przechowywane w pamięci
- Immutable
- Lazy evaluated
- Parallel - przetwarzane równolegle
- Partitioned - rozproszone
WAŻNE informacje !
Ważne do zrozumienia działania SPARKA:
| Term | Definition |
|---|---|
| RDD | Resilient Distributed Dataset |
| Transformation | Spark operation that produces an RDD |
| Action | Spark operation that produces a local object |
| Spark Job | Sequence of transformations on data with a final action |
Dwie podstawowe metody tworzenia RDD:
| Method | Result |
|---|---|
sc.parallelize(array) |
Create RDD of elements of array (or list) |
sc.textFile(path/to/file) |
Create RDD of lines from file |
Podstawowe transformacje
| Transformation Example | Result |
|---|---|
filter(lambda x: x % 2 == 0) |
Discard non-even elements |
map(lambda x: x * 2) |
Multiply each RDD element by 2 |
map(lambda x: x.split()) |
Split each string into words |
flatMap(lambda x: x.split()) |
Split each string into words and flatten sequence |
sample(withReplacement=True,0.25) |
Create sample of 25% of elements with replacement |
union(rdd) |
Append rdd to existing RDD |
distinct() |
Remove duplicates in RDD |
sortBy(lambda x: x, ascending=False) |
Sort elements in descending order |
Podstawowe akcje
| Action | Result |
|---|---|
collect() |
Convert RDD to in-memory list |
take(3) |
First 3 elements of RDD |
top(3) |
Top 3 elements of RDD |
takeSample(withReplacement=True,3) |
Create sample of 3 elements with replacement |
sum() |
Find element sum (assumes numeric elements) |
mean() |
Find element mean (assumes numeric elements) |
stdev() |
Find element deviation (assumes numeric elements) |
keywords = ['Books', 'DVD', 'CD', 'PenDrive']
key_rdd = sc.parallelize(keywords)
key_rdd.collect()key_small = key_rdd.map(lambda x: x.lower()) # transformacjakey_small.collect() # akcja sc.stop()Spark’s core data structure
✅: A low level object that lets Spark work its magic by splitting data across multiple nodes in the cluster.
❌: However, RDDs are hard to work with directly, so we’ll be using the Spark DataFrame abstraction built on top of RDDs.
MAP REDUCE
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("new").getOrCreate()
# otrzymanie obiektu SparkContext
sc = spark.sparkContextimport re
# Word Count on RDD
sc.textFile("MobyDick.txt")\
.map(lambda x: re.findall(r"[a-z']+", x.lower())) \
.flatMap(lambda x: [(y, 1) for y in x]).reduceByKey(lambda x,y: x + y)\
.take(5)SPARK STREAMING
Część Sparka odpowiedzialna za przetwarzanie danych w czasie rzeczywistym.

Dane mogą pochodzić z różnych źródeł np. sokety TCP, Kafka, etc. Korzystając z poznanych już metod map, reduce, join, oraz window można w łatwy sposób generować przetwarzanie strumienia tak jaby był to nieskończony ciąg RDD. Ponadto nie ma problemu aby wywołać na strumieniu operacje ML czy wykresy.
Cała procedura przedstawia się następująco:

SPARK STREAMING w tej wersji wprowadza abstrakcje zwaną discretized stream DStream (reprezentuje sekwencję RDD).
Operacje na DStream można wykonywać w API JAVA, SCALA, Python, R (nie wszystkie możliwości są dostępne dla Pythona).
Spark Streaming potrzebuje minium 2 rdzenie.
- StreamingContext(sparkContext, batchDuration) - reprezentuje połączenie z klastrem i służy do tworzenia DStreamów,
batchDurationwskazuje na granularność batch’y (w sekundach) - socketTextStream(hostname, port) - tworzy DStream na podstawie danych napływających ze wskazanego źródła TCP
- flatMap(f), map(f), reduceByKey(f) - działają analogicznie jak w przypadku RDD z tym że tworzą nowe DStream’y
- pprint(n) - printuje pierwsze
n(domyślnie 10) elementów z każdego RDD wygenerowanego w DStream’ie - StreamingContext.start() - rozpoczyna działania na strumieniach
- StreamingContext.awaitTermination(timeout) - oczekuje na zakończenie działań na strumieniach
- StreamingContext.stop(stopSparkContext, stopGraceFully) - kończy działania na strumieniach
Obiekt StreamingContext można wygenerować za pomocą obiektu SparkContext.
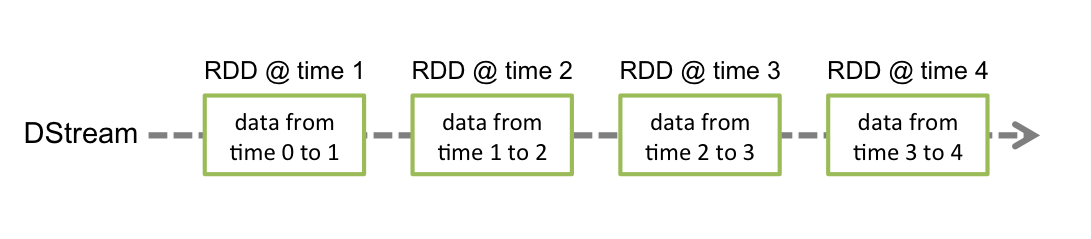
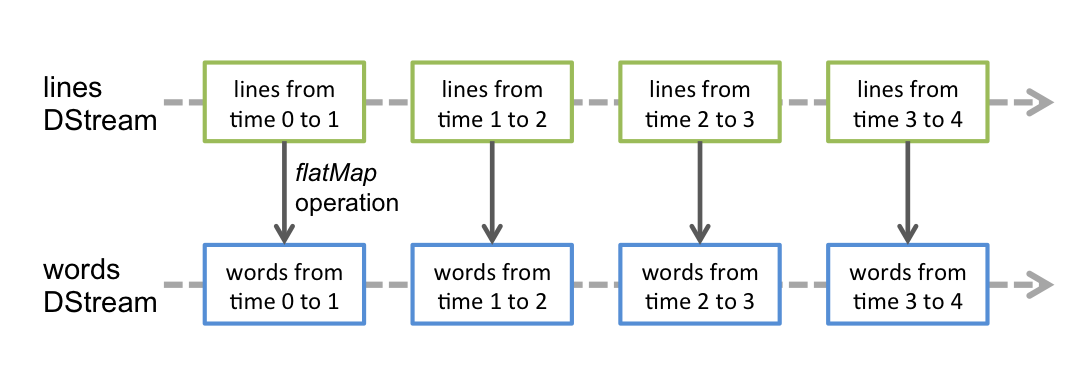
import re
from pyspark import SparkContext
from pyspark.streaming import StreamingContext
# Create a local StreamingContext with two working thread
# and batch interval of 1 second
sc = SparkContext("local[2]", "NetworkWordCount2")
ssc = StreamingContext(sc, 2)
# DStream
lines = ssc.socketTextStream("localhost", 9998)
# podziel każdą linię na wyrazy
# DStream jest mapowany na kolejny DStream
# words = lines.flatMap(lambda line: line.split(" "))
words = lines.flatMap(lambda x: re.findall(r"[a-z']+", x.lower()))
# zliczmy każdy wyraz w każdym batchu
# DStream jest mapowany na kolejny DStream
# pairs = words.map(lambda word: (word, 1))
# DStream jest mapowany na kolejny DStream
# wordCounts = pairs.reduceByKey(lambda x, y: x + y)
wordCounts = words.map(lambda word: (word,1)).reduceByKey(lambda x,y: x+y)
# wydrukuj pierwszy element
wordCounts.pprint()# before start run a stream data
ssc.start() # Start the computation
ssc.awaitTermination()
ssc.stop()
sc.stop()# w konsoli linuxowej netcat Nmap for windows
!nc -lk 9998%%file start_stream.py
from socket import *
import time
rdd = list()
with open("MobyDick_full.txt", 'r') as ad:
for line in ad:
rdd.append(line)
HOST = 'localhost'
PORT = 9998
ADDR = (HOST, PORT)
tcpSock = socket(AF_INET, SOCK_STREAM)
tcpSock.bind(ADDR)
tcpSock.listen(5)
while True:
c, addr = tcpSock.accept()
print('got connection')
for line in rdd:
try:
c.send(line.encode())
time.sleep(1)
except:
break
c.close()
print('disconnected')