Dane nieustrukturyzowane to dane, które nie są w żaden sposób uporządkowane, takie jak:
obrazy,
teksty,
dźwięki,
wideo.
Niezależnie od typu, wszystko przetwarzamy w tensorach (macierzach wielowymiarowych). To może prowadzić do chęci wykorzystania modeli ML i sieci neuronowych do analizy danych nieustrukturyzowanych.
import numpy as npimport seaborn as snsimport matplotlib.pyplot as pltsns.set(style="whitegrid", palette="husl")# 2-dim picture 28 x 28 pixelpicture_2d = np.random.uniform(size=(28,28))picture_2d[0:5,0:5]
/Users/seba/Documents/GitHub/RTA_2025/venv/lib/python3.11/site-packages/torchvision/models/_utils.py:208: UserWarning: The parameter 'pretrained' is deprecated since 0.13 and may be removed in the future, please use 'weights' instead.
warnings.warn(
/Users/seba/Documents/GitHub/RTA_2025/venv/lib/python3.11/site-packages/torchvision/models/_utils.py:223: UserWarning: Arguments other than a weight enum or `None` for 'weights' are deprecated since 0.13 and may be removed in the future. The current behavior is equivalent to passing `weights=AlexNet_Weights.IMAGENET1K_V1`. You can also use `weights=AlexNet_Weights.DEFAULT` to get the most up-to-date weights.
warnings.warn(msg)
Downloading: "https://download.pytorch.org/models/alexnet-owt-7be5be79.pth" to /Users/seba/.cache/torch/hub/checkpoints/alexnet-owt-7be5be79.pth
100%|██████████| 233M/233M [00:03<00:00, 67.9MB/s]
Przykładowy model sieci nueronowej (bez konwolucji) - czy sądzisz, że to dobre rozwiązanie?
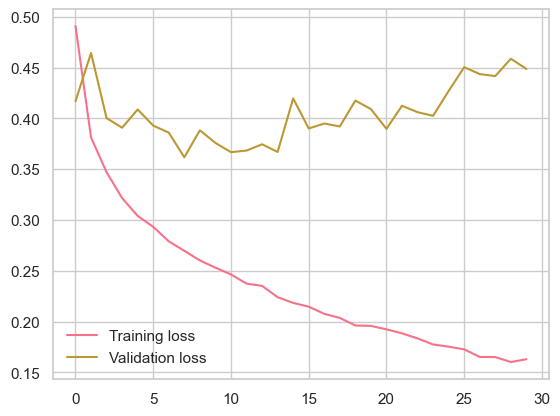
# Define the network architecturefrom torch import nn, optimimport torch.nn.functional as Fmodel = nn.Sequential(nn.Linear(784, 128), nn.ReLU(), nn.Linear(128, 10), nn.LogSoftmax(dim =1) )# Define the losscriterion = nn.NLLLoss()# Define the optimizeroptimizer = optim.Adam(model.parameters(), lr =0.002)# Define the epochsepochs =30train_losses, test_losses = [], []for e inrange(epochs): running_loss =0for images, labels in trainloader:# Flatten Fashion-MNIST images into a 784 long vector images = images.view(images.shape[0], -1)# Training pass optimizer.zero_grad() output = model.forward(images) loss = criterion(output, labels) loss.backward() optimizer.step() running_loss += loss.item()else: test_loss =0 accuracy =0# Turn off gradients for validation, saves memory and computationwith torch.no_grad():# Set the model to evaluation mode model.eval()# Validation passfor images, labels in testloader: images = images.view(images.shape[0], -1) log_ps = model(images) test_loss += criterion(log_ps, labels) ps = torch.exp(log_ps) top_p, top_class = ps.topk(1, dim =1) equals = top_class == labels.view(*top_class.shape) accuracy += torch.mean(equals.type(torch.FloatTensor)) model.train() train_losses.append(running_loss/len(trainloader)) test_losses.append(test_loss/len(testloader))print("Epoch: {}/{}..".format(e+1, epochs),"Training loss: {:.3f}..".format(running_loss/len(trainloader)),"Test loss: {:.3f}..".format(test_loss/len(testloader)),"Test Accuracy: {:.3f}".format(accuracy/len(testloader)))
Epoch: 1/30.. Training loss: 0.491.. Test loss: 0.417.. Test Accuracy: 0.849
Epoch: 2/30.. Training loss: 0.381.. Test loss: 0.464.. Test Accuracy: 0.832
Epoch: 3/30.. Training loss: 0.347.. Test loss: 0.400.. Test Accuracy: 0.854
Epoch: 4/30.. Training loss: 0.321.. Test loss: 0.391.. Test Accuracy: 0.857
Epoch: 5/30.. Training loss: 0.304.. Test loss: 0.409.. Test Accuracy: 0.856
Epoch: 6/30.. Training loss: 0.293.. Test loss: 0.393.. Test Accuracy: 0.861
Epoch: 7/30.. Training loss: 0.279.. Test loss: 0.386.. Test Accuracy: 0.865
Epoch: 8/30.. Training loss: 0.270.. Test loss: 0.362.. Test Accuracy: 0.879
Epoch: 9/30.. Training loss: 0.260.. Test loss: 0.388.. Test Accuracy: 0.868
Epoch: 10/30.. Training loss: 0.253.. Test loss: 0.376.. Test Accuracy: 0.877
Epoch: 11/30.. Training loss: 0.246.. Test loss: 0.367.. Test Accuracy: 0.879
Epoch: 12/30.. Training loss: 0.237.. Test loss: 0.368.. Test Accuracy: 0.880
Epoch: 13/30.. Training loss: 0.235.. Test loss: 0.374.. Test Accuracy: 0.877
Epoch: 14/30.. Training loss: 0.224.. Test loss: 0.367.. Test Accuracy: 0.877
Epoch: 15/30.. Training loss: 0.218.. Test loss: 0.420.. Test Accuracy: 0.865
Epoch: 16/30.. Training loss: 0.215.. Test loss: 0.390.. Test Accuracy: 0.874
Epoch: 17/30.. Training loss: 0.208.. Test loss: 0.395.. Test Accuracy: 0.876
Epoch: 18/30.. Training loss: 0.204.. Test loss: 0.392.. Test Accuracy: 0.880
Epoch: 19/30.. Training loss: 0.196.. Test loss: 0.417.. Test Accuracy: 0.878
Epoch: 20/30.. Training loss: 0.196.. Test loss: 0.409.. Test Accuracy: 0.878
Epoch: 21/30.. Training loss: 0.192.. Test loss: 0.390.. Test Accuracy: 0.880
Epoch: 22/30.. Training loss: 0.188.. Test loss: 0.412.. Test Accuracy: 0.885
Epoch: 23/30.. Training loss: 0.183.. Test loss: 0.406.. Test Accuracy: 0.883
Epoch: 24/30.. Training loss: 0.178.. Test loss: 0.402.. Test Accuracy: 0.884
Epoch: 25/30.. Training loss: 0.175.. Test loss: 0.427.. Test Accuracy: 0.878
Epoch: 26/30.. Training loss: 0.173.. Test loss: 0.450.. Test Accuracy: 0.882
Epoch: 27/30.. Training loss: 0.165.. Test loss: 0.444.. Test Accuracy: 0.882
Epoch: 28/30.. Training loss: 0.165.. Test loss: 0.442.. Test Accuracy: 0.881
Epoch: 29/30.. Training loss: 0.160.. Test loss: 0.459.. Test Accuracy: 0.876
Epoch: 30/30.. Training loss: 0.163.. Test loss: 0.449.. Test Accuracy: 0.882
print("My model: \n\n", model, "\n")print("The state dict keys: \n\n", model.state_dict().keys())
My model:
Sequential(
(0): Linear(in_features=784, out_features=128, bias=True)
(1): ReLU()
(2): Linear(in_features=128, out_features=10, bias=True)
(3): LogSoftmax(dim=1)
)
The state dict keys:
odict_keys(['0.weight', '0.bias', '2.weight', '2.bias'])
torch.save(model.state_dict(), 'checkpoint.pth')
A jakie inne sieci i warstwy możemy wykorzystać do analizy danych nieustrukturyzowanych?
Znajdź odpowiedź na to pytanie w dokumentacji biblioteki PyTorch.
Dane tekstowe i model Worka słów
import pandas as pddf_train = pd.read_csv("train.csv")df_train = df_train.drop("index", axis=1)print(df_train.head())print(np.bincount(df_train["label"]))
text label
0 When we started watching this series on cable,... 1
1 Steve Biko was a black activist who tried to r... 1
2 My short comment for this flick is go pick it ... 1
3 As a serious horror fan, I get that certain ma... 0
4 Robert Cummings, Laraine Day and Jean Muir sta... 1
[17452 17548]
# BoW model - wektoryzator z sklearnfrom sklearn.feature_extraction.text import CountVectorizercv = CountVectorizer(lowercase=True, max_features=10_000, stop_words="english")cv.fit(df_train["text"])
In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
Teraz drobna modyfikacja - wiemy, że takiej zmiennej nie chcemy do modelu - ma tylko jedną wartość. Ale jak zweryfikować jakie to zmienne jeśli masz 3 mln kolumn?
numeric_features = ['math score','reading score','writing score', 'bad_feature']# znajdz sposób na automatyczny podział dla zmiennych numerycznych i nienumerycznych
Laboratorium rozpoczyna się od przedstawienia danych nieustrukturyzowanych, takich jak obrazy, teksty, dźwięki czy wideo. Podkreślono, że niezależnie od typu danych, wszystko przetwarzane jest w tensorach (macierzach wielowymiarowych), co umożliwia wykorzystanie modeli uczenia maszynowego i sieci neuronowych do ich analizy.
Praca z obrazami
Ćwiczenia pokazują, jak za pomocą bibliotek NumPy i Matplotlib generować i wizualizować obrazy dwuwymiarowe. Następnie wprowadzono bibliotekę PyTorch i jej moduł torchvision do przetwarzania obrazów, w tym: • Pobieranie i wczytywanie obrazów z internetu • Transformacje obrazów (zmiana rozmiaru, przycinanie, normalizacja) • Konwersja obrazów do tensorów • Tworzenie batchy danych
Wykorzystanie pretrenowanych modeli
Laboratorium demonstruje, jak załadować i wykorzystać pretrenowany model AlexNet z biblioteki torchvision.models do klasyfikacji obrazów. Pokazano również, jak przygotować dane wejściowe i uzyskać predykcje z modelu.
Praca z danymi tekstowymi
W dalszej części laboratorium wprowadzono analizę danych tekstowych za pomocą modelu worka słów (bag-of-words). Pokazano, jak przekształcić teksty na reprezentacje numeryczne, które mogą być wykorzystane w modelach uczenia maszynowego.
Obiektowe podejście do modelowania
Na koniec laboratorium przedstawiono obiektowe podejście do tworzenia modeli w PyTorch, co jest istotne przy budowie bardziej złożonych architektur sieci neuronowych.
⸻
💡 Propozycje rozszerzeń
Aby jeszcze bardziej wzbogacić laboratorium 4, można rozważyć dodanie następujących elementów:
Wykorzystanie innych pretrenowanych modeli
Dodanie przykładów z wykorzystaniem innych pretrenowanych modeli, takich jak ResNet czy VGG, pozwoliłoby studentom porównać różne architektury i ich zastosowania.
Finałowy projekt integrujący obrazy i tekst
Zaproponowanie projektu, w którym studenci łączą analizę obrazów i tekstów (np. klasyfikacja memów), umożliwiłoby praktyczne zastosowanie zdobytej wiedzy.
Wprowadzenie do transfer learningu
Pokazanie, jak dostosować pretrenowane modele do nowych zadań poprzez transfer learning, przygotowałoby studentów do pracy z ograniczonymi zbiorami danych.
Analiza danych dźwiękowych
Dodanie sekcji dotyczącej analizy danych dźwiękowych (np. rozpoznawanie mowy) rozszerzyłoby zakres omawianych danych nieustrukturyzowanych.
Wykorzystanie bibliotek NLP
Wprowadzenie bibliotek takich jak spaCy czy Hugging Face Transformers do analizy tekstu pozwoliłoby na bardziej zaawansowane przetwarzanie języka naturalnego.
⸻
✅ Podsumowanie
Laboratorium 4 stanowi solidne wprowadzenie do analizy danych nieustrukturyzowanych z wykorzystaniem bibliotek NumPy i PyTorch. Dodanie powyższych rozszerzeń mogłoby jeszcze bardziej zwiększyć wartość edukacyjną zajęć, przygotowując studentów do realnych wyzwań w pracy z różnorodnymi danymi w kontekście Big Data.