from pyspark import SparkContext
sc = SparkContext(appName="myAppName")Apache Spark z plikami RDD
RDD
- Resilient Distributed Dataset
- Podstawowa abstrakcja oraz rdzeń Sparka
- Obsługiwane przez dwa rodzaje operacji:
- Akcje:
- operacje uruchamiające egzekucję transformacji na RDD
- przyjmują RDD jako input i zwracają wynik NIE będący RDD
- Transformacje:
- leniwe operacje
- przyjmują RDD i zwracają RDD
- Akcje:
- In-Memory - dane RDD przechowywane w pamięci
- Immutable
- Lazy evaluated
- Parallel - przetwarzane równolegle
- Partitioned - rozproszone
WAŻNE informacje !
Ważne do zrozumienia działania SPARKA:
| Term | Definition |
|---|---|
| RDD | Resilient Distributed Dataset |
| Transformation | Spark operation that produces an RDD |
| Action | Spark operation that produces a local object |
| Spark Job | Sequence of transformations on data with a final action |
Dwie podstawowe metody tworzenia RDD:
| Method | Result |
|---|---|
sc.parallelize(array) |
Create RDD of elements of array (or list) |
sc.textFile(path/to/file) |
Create RDD of lines from file |
Podstawowe transformacje
| Transformation Example | Result |
|---|---|
filter(lambda x: x % 2 == 0) |
Discard non-even elements |
map(lambda x: x * 2) |
Multiply each RDD element by 2 |
map(lambda x: x.split()) |
Split each string into words |
flatMap(lambda x: x.split()) |
Split each string into words and flatten sequence |
sample(withReplacement=True,0.25) |
Create sample of 25% of elements with replacement |
union(rdd) |
Append rdd to existing RDD |
distinct() |
Remove duplicates in RDD |
sortBy(lambda x: x, ascending=False) |
Sort elements in descending order |
Podstawowe akcje
| Action | Result |
|---|---|
collect() |
Convert RDD to in-memory list |
take(3) |
First 3 elements of RDD |
top(3) |
Top 3 elements of RDD |
takeSample(withReplacement=True,3) |
Create sample of 3 elements with replacement |
sum() |
Find element sum (assumes numeric elements) |
mean() |
Find element mean (assumes numeric elements) |
stdev() |
Find element deviation (assumes numeric elements) |
keywords = ['Books', 'DVD', 'CD', 'PenDrive'] # nasze dane
key_rdd = sc.parallelize(keywords) # metoda parallelize - "wczyta dane"
key_rdd.collect() # akcja wyświetlania key_small = key_rdd.map(lambda x: x.lower()) # transformacja
key_small.collect() # akcja sc.stop()Map reduce
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("new").getOrCreate()
# otrzymanie obiektu SparkContext
sc = spark.sparkContexttekst = sc.textFile("MobyDick.txt")
tekst.take(5)import re
# Word Count on RDD
sc.textFile("MobyDick.txt")\
.map(lambda x: re.findall(r"[a-z']+", x.lower())) \
.flatMap(lambda x: [(y, 1) for y in x]).reduceByKey(lambda x,y: x + y)\
.take(5)sc.stop()SPARK STREAMING
Część Sparka odpowiedzialna za przetwarzanie danych w czasie rzeczywistym.

Dane mogą pochodzić z różnych źródeł np. sokety TCP, Kafka, etc. Korzystając z poznanych już metod map, reduce, join, oraz window można w łatwy sposób generować przetwarzanie strumienia tak jaby był to nieskończony ciąg RDD. Ponadto nie ma problemu aby wywołać na strumieniu operacje ML czy wykresy.
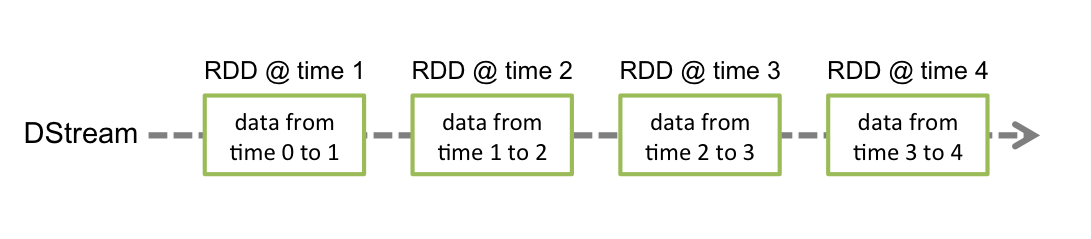
Cała procedura przedstawia się następująco:

SPARK STREAMING w tej wersji wprowadza abstrakcje zwaną discretized stream DStream (reprezentuje sekwencję RDD).
Operacje na DStream można wykonywać w API JAVA, SCALA, Python, R (nie wszystkie możliwości są dostępne dla Pythona).
Spark Streaming potrzebuje minium 2 rdzenie.
- StreamingContext(sparkContext, batchDuration) - reprezentuje połączenie z klastrem i służy do tworzenia DStreamów,
batchDurationwskazuje na granularność batch’y (w sekundach) - socketTextStream(hostname, port) - tworzy DStream na podstawie danych napływających ze wskazanego źródła TCP
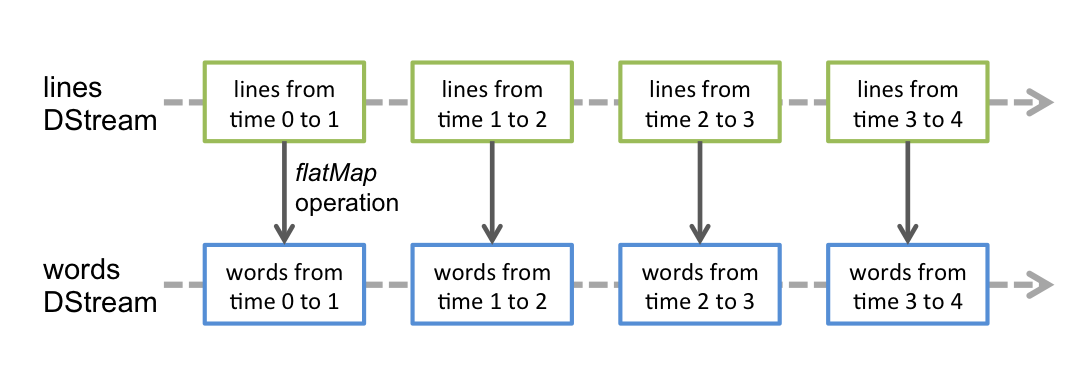
- flatMap(f), map(f), reduceByKey(f) - działają analogicznie jak w przypadku RDD z tym że tworzą nowe DStream’y
- pprint(n) - printuje pierwsze
n(domyślnie 10) elementów z każdego RDD wygenerowanego w DStream’ie - StreamingContext.start() - rozpoczyna działania na strumieniach
- StreamingContext.awaitTermination(timeout) - oczekuje na zakończenie działań na strumieniach
- StreamingContext.stop(stopSparkContext, stopGraceFully) - kończy działania na strumieniach
Obiekt StreamingContext można wygenerować za pomocą obiektu SparkContext.
import re
from pyspark import SparkContext
from pyspark.streaming import StreamingContext
# Create a local StreamingContext with two working thread
# and batch interval of 1 second
sc = SparkContext("local[2]", "NetworkWordCount2")
ssc = StreamingContext(sc, 2)
# DStream
lines = ssc.socketTextStream("localhost", 9998)
# podziel każdą linię na wyrazy
# DStream jest mapowany na kolejny DStream
# words = lines.flatMap(lambda line: line.split(" "))
words = lines.flatMap(lambda x: re.findall(r"[a-z']+", x.lower()))
# zliczmy każdy wyraz w każdym batchu
# DStream jest mapowany na kolejny DStream
# pairs = words.map(lambda word: (word, 1))
# DStream jest mapowany na kolejny DStream
# wordCounts = pairs.reduceByKey(lambda x, y: x + y)
wordCounts = words.map(lambda word: (word,1)).reduceByKey(lambda x,y: x+y)
# wydrukuj pierwszy element
wordCounts.pprint()# w konsoli linuxowej netcat Nmap for windows
!nc -lk 9998# before starting, run a stream data
ssc.start() # Start the computation
ssc.awaitTermination()
ssc.stop()
sc.stop()przesylanie strumienia przez socket
nc -lk 9998%%file start_stream.py
from socket import *
import time
rdd = list()
with open("MobyDick.txt", 'r') as ad:
for line in ad:
rdd.append(line)
HOST = 'localhost'
PORT = 9998
ADDR = (HOST, PORT)
tcpSock = socket(AF_INET, SOCK_STREAM)
tcpSock.bind(ADDR)
tcpSock.listen(5)
while True:
c, addr = tcpSock.accept()
print('got connection')
for line in rdd:
try:
c.send(line.encode())
time.sleep(1)
except:
break
c.close()
print('disconnected')%%file streamWordCount.py
from pyspark.sql import SparkSession
from pyspark.sql.functions import explode, split
if __name__ == "__main__":
spark = SparkSession.builder.appName("Stream_DF").getOrCreate()
spark.sparkContext.setLogLevel("ERROR")
lines = (spark
.readStream
.format("socket")
.option("host", "localhost")
.option("port", 9998)
.load())
words = lines.select(explode(split(lines.value, " ")).alias("word"))
word_counts = words.groupBy("word").count()
streamingQuery = (word_counts
.writeStream
.format("console")
.outputMode("complete")
.trigger(processingTime="5 second")
.start())
streamingQuery.awaitTermination()
from pyspark.sql import SparkSession
from pyspark.sql.functions import explode, split
batch_counter = {"count": 0}
def process_batch(df, batch_id):
batch_counter["count"] += 1
print(f"Batch ID: {batch_id}")
df.show(truncate=False)
spark = SparkSession.builder.appName("Stream_DF").getOrCreate()
spark.sparkContext.setLogLevel("ERROR")
lines = (spark
.readStream
.format("socket")
.option("host", "localhost")
.option("port", 9998)
.load())
words = lines.select(explode(split(lines.value, " ")).alias("word"))
word_counts = words.groupBy("word").count()
streamingQuery = (word_counts.writeStream
.format("console")
.outputMode("complete")
.foreachBatch(process_batch)
.trigger(processingTime="5 second")
.start())Przetwarzanie danych strumieniowych
- Sprawdź czy serwer Kafki posiada jakieś zdefiniowane topici:
cd ~
kafka/bin/kafka-topics.sh --list --bootstrap-server broker:9092- dodaj topic o nazwie
streamXXGdzie zaXwstaw nr grupy a zaxxnr swojego serwera
cd ~
kafka/bin/kafka-topics.sh --bootstrap-server broker:9092 --create --topic streamXXsprawdź listę tematów ponownie upewniając się, że posiadasz temat
streamXXUruchom nowy terminal na swoim komputerze i utwórz producenta generującego dane do nowego topicu
cd ~
kafka/bin/kafka-console-producer.sh --bootstrap-server broker:9092 --topic streamAby sprawdzić czy wysyłanie wiadomości działa uruchom kolejne okno terminala i wpisz następującą komendę realizującą konsumenta:
cd ~
kafka/bin/kafka-console-consumer.sh --bootstrap-server broker:9092 --topic streamXX Zweryfikuj, że przesyłanie danych działa.
Zamknij okno producenta. Okno konsumenta zostaw otwarte - przyda się do weryfikacji automatu generującego dane.
Uruchomienie kodu wysyłającego strumień
Uzupełnij skrypt tak by generował następujące dane:
- utwórz zmienną
messagektóra będzie słownikiem zawierającym informacje pojedynczego eventu (klucz: wartość):- “time” : aktualny czas w postaci stringu datetime.now()
- “id” : wybierane losowo z listy [“a”, “b”, “c”, “d”, “e”]
- “value: losowa wartość z zakresu 0 do 100
%%file stream.py
import json
import random
import sys
from datetime import datetime
from time import sleep
from kafka import KafkaProducer
KAFKA_SERVER = "broker:9092"
TOPIC = 'stream'
LAG = 2
def create_producer(server):
return KafkaProducer(
bootstrap_servers=[server],
value_serializer=lambda x: json.dumps(x).encode("utf-8"),
api_version=(3, 7, 0),
)
if __name__ == "__main__":
producer = create_producer(KAFKA_SERVER)
try:
while True:
message = {
"time" : str(datetime.now() ) ,
"id" : random.choice(["a", "b", "c", "d", "e"]) ,
"temperatura" : random.randint(-100,100) ,
"cisnienie" : random.randint(0,50) ,
}
producer.send(TOPIC, value=message)
sleep(LAG)
except KeyboardInterrupt:
producer.close()Overwriting stream.py- w terminalu jupyterlab uruchom plik
stream.py
python stream.pysprawdz w oknie consumenta czy wysyłane wiadomości przychodzą do Kafki.
Za uruchomienie importu kafka odpowiedzialna jest biblioteka kafka-python którą możesz zainstalować poleceniem pip install kafka-python
APACHE SPARK
Przygotuj kod skryptu który pobierze informacje z przesyłanego strumienia danych.
%%file app.py
# spark-submit --packages org.apache.spark:spark-sql-kafka-0-10_2.12:3.1.1 app.py
from pyspark.sql import SparkSession
from pyspark.sql.functions import *
from pyspark.sql.types import *
SERVER = "broker:9092"
TOPIC = 'stream'
schema = StructType(
[
StructField("time", TimestampType()),
StructField("id", StringType()),
StructField("temperatura", IntegerType()),
StructField("cisnienie", IntegerType()),
]
)
SCHEMA = """time Timestamp, id String, temperatura Int, cisnienie Int """ # DDL string
if __name__ == "__main__":
spark = SparkSession.builder.getOrCreate()
spark.sparkContext.setLogLevel("WARN")
raw = (
spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", SERVER)
.option("subscribe", TOPIC)
.load()
)
# query = (
# raw.writeStream
# .outputMode("append")
# .format("console")
# .option("truncate", False)
# .start()
# )
parsed = (raw.select("timestamp", from_json(decode(col("value"), "utf-8"), SCHEMA).alias("moje_dane"))
.select("timestamp", "moje_dane.*")
)
# query = (
# parsed.writeStream
# .outputMode("append")
# .format("console")
# .option("truncate", False)
# .start()
# )
# gr = parsed.agg(avg("temperatura"), avg("cisnienie"))
# query = (gr.writeStream
# .outputMode("update")
# .format("console")
# .option("truncate", False)
# .start()
# )
gr = (parsed.withWatermark("timestamp", "5 seconds")
.groupBy(window("timestamp", "10 seconds", "7 seconds"))
.agg(avg("temperatura"), avg("cisnienie"))
)
query = (gr.writeStream
.outputMode("complete")
.format("console")
.option("truncate", False)
.start()
)
query.awaitTermination()Overwriting app.py