Analiza Danych w czasie rzeczywistym kurs dla studentów SGH
Ćwiczenia 6 - Apache Spark StreamingContext
Licznik wyrazów w wersji stacjonarnej
Prosty licznik wyrazów wygenerowany na podstawie pliku tekstowego.
from pyspark.sql import SparkSession
spark = SparkSession.builder\
.appName("new")\
.getOrCreate()
# otrzymanie obiektu SparkContext
sc = spark.sparkContext
import re
# Word Count on RDD
sc.textFile("RDD_input") \
.map(lambda x: re.findall(r"[a-z']+", x.lower())) \
.flatMap(lambda x: [(y, 1) for y in x]) \
.reduceByKey(lambda x, y: x + y) \
.collect()
SPARK STREAMING
Część Sparka odpowiedzialna za przetwarzanie danych w czasie rzeczywistym.

Dane mogą pochodzić z różnych źródeł np. sokety TCP, Kafka, etc.
Korzystając z poznanych już metod map, reduce, join, oraz window można w łatwy sposób generować przetwarzanie strumienia tak jakby był to nieskończony ciąg RDD.
Ponadto nie ma problemu aby wywołać na strumieniu operacje ML czy wykresy.
Cała procedura przedstawia się następująco:

SPARK STREAMING w tej wersji wprowadza abstrakcje zwaną discretized stream DStream (reprezentuje sekwencję RDD).
Operacje na DStream można wykonywać w API JAVA, SCALA, Python, R (nie wszystkie możliwości są dostępne dla Pythona).
Spark Streaming potrzebuje minimum 2 rdzenie.
- StreamingContext(sparkContext, batchDuration) - reprezentuje połączenie z klastrem i służy do tworzenia DStreamów,
batchDurationwskazuje na granularność batch’y (w sekundach) - socketTextStream(hostname, port) - tworzy DStream na podstawie danych napływających ze wskazanego źródła TCP
- flatMap(f), map(f), reduceByKey(f) - działają analogicznie jak w przypadku RDD z tym że tworzą nowe DStream’y
- pprint(n) - wypisuje pierwsze
n(domyślnie 10) elementów z każdego RDD wygenerowanego w DStream’ie - StreamingContext.start() - rozpoczyna działania na strumieniach
- StreamingContext.awaitTermination(timeout) - oczekuje na zakończenie działań na strumieniach
- StreamingContext.stop(stopSparkContext, stopGraceFully) - kończy działania na strumieniach
Obiekt StreamingContext można wygenerować za pomocą obiektu SparkContext.
import re
from pyspark import SparkContext
from pyspark.streaming import StreamingContext
sc = SparkContext("local[2]", "NetworkWordCount")
ssc = StreamingContext(sc, 1)
# DStream
lines = ssc.socketTextStream("localhost", 9999)
# podziel każdą linię na wyrazy
# DStream jest mapowany na kolejny DStream
words = lines.flatMap(lambda x: re.findall(r"[a-z']+", x.lower()))
# zliczmy każdy wyraz w każdym batchu
wordCounts = words.map(lambda word: (word,1)).reduceByKey(lambda x,y: x+y)
# wydrukuj pierwszy element
wordCounts.pprint()
ssc.start() # Start the computation
ssc.awaitTermination() # Wait for the computation to terminate
ssc.stop(True,True)
Po uruchomieniu powyższego kodu należy wygenerować tekst źródłowy nadawany na porcie 9999. Można posłużyć się w tym celu narzędziem netcat (na windowsie Nmap) W konsoli bash wykonaj:
nc -lk 9999
Python to język programowania używany do zastosowań ogólnych. Dlatego mamy możliwość napisania swojego kodu realizującego wypisywanie komunikatów tekstowych na porcie 9999.
Przykładowy kod może wyglądać tak:
from socket import *
import time
rdd = list()
with open("RDD_input", 'r') as ad:
for line in ad:
rdd.append(line)
HOST = 'localhost'
PORT = 9999
ADDR = (HOST, PORT)
tcpSock = socket(AF_INET, SOCK_STREAM)
tcpSock.bind(ADDR)
tcpSock.listen(5)
while True:
c, addr = tcpSock.accept()
print('got connection')
for line in rdd:
try:
c.send(line.encode())
time.sleep(1)
except:
break
c.close()
print('disconnected')
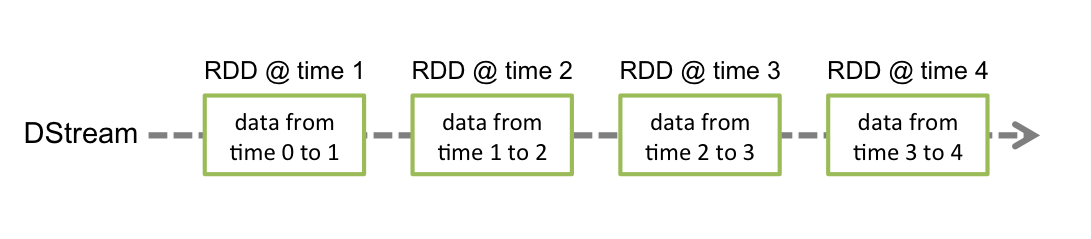
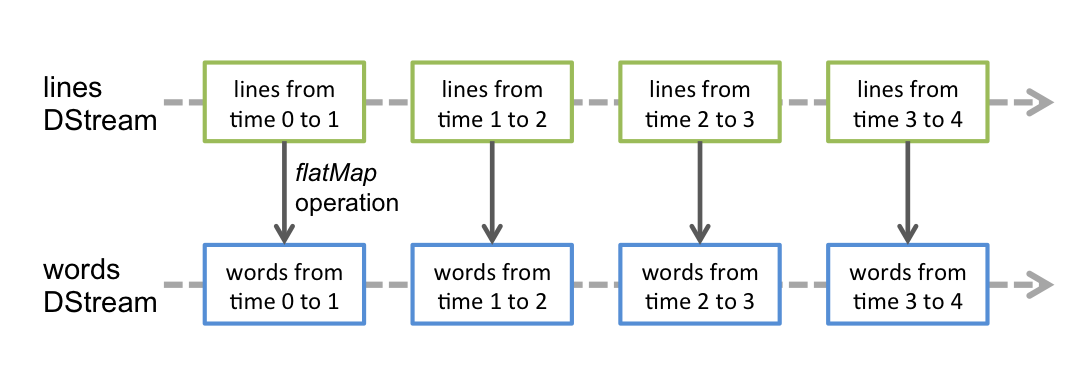
W celach ćwiczeniowych i testowania przetwarzania strumieniowego warto wykorzystać Obiekt Kolejki wygenerowany z obiektów RDD. Każdy RDD wepchany (pushed) do kolejki traktowany jest jako batch w DStream i przetwarzany jest jako strumień.
import re
from pyspark import SparkContext
from pyspark.streaming import StreamingContext
sc = SparkContext("local[2]", "NetworkWordCount3")
ssc = StreamingContext(sc, 2)
rddQueue = []
for i in range(10):
rddQueue += [sc.parallelize(
[j for j in range(1, 1001)], 10)]
inputStream = ssc.queueStream(rddQueue)
mappedStream = inputStream.map(lambda x: (x % 10, 1))
reducedStream = mappedStream.reduceByKey(lambda a, b: a + b)
reducedStream.pprint()
import time
ssc.start()
time.sleep(10)
ssc.stop(stopSparkContext=True, stopGraceFully=True)
Stateful Wordcount
Operacja updateStateByKey pozwala łączyć ze sobą wyniki otrzymywane na poszczególbych DStreamach. Dzięki tej operacji możesz w sposób ciągły uzupełniać informacje !
Aby Spark Streaming mógł łączyć dane z wielu batchy (stateful transformations) konieczne jest wskazanie lokalizacji gdzie zapisywane będą checkpointy.
- Zdefiniuj stan podstawowy
- wskaż funkcję łączącą
- checkpoint(directory) - wskazuje gdzie zapisywane będą checkpointy z operacji na DStream’ach
- updateStateByKey(updateFunc) - zwraca nowy DStream zawierający informację o bieżącym stanie poszczególnych kluczy, stan każdego klucza odświeżany jest przy pomocy
updateFunc
def updateFunc(newValues, runningCount):
if runningCount is None:
runningCount = 0
return sum(newValues, runningCount)
import re
from pyspark import SparkContext
from pyspark.streaming import StreamingContext
sc = SparkContext("local[2]", "NetworkWC3")
ssc = StreamingContext(sc, 5)
ssc.checkpoint("tmp")
lines = ssc.socketTextStream("localhost", 9999)
words = lines.flatMap(lambda x: re.findall(r"[a-z']+", x.lower()))
pairs = words.map(lambda word: (word, 1))
runningCounts = pairs.updateStateByKey(updateFunc)
runningCounts.pprint()
ssc.start()
ssc.awaitTermination()
ssc.stop(True,True)
Zadanie - Korzystając z danych kolejki rddQueue dodaj wszystkie elementy do siebie
Redukcja w oknach
- reduceByKeyAndWindow(func, invFunc, windowDuration, slideDuration) - zwraca nowy DStream powstały w wyniku stosowania przyrostowo reduceByKey wewnątrz zdefiniowanego okna. Zredukowane wartości dla nowego okna obliczane są z wykorzystaniem wartości starego okna poprzez:
- zredukowanie (dodanie) nowych wartości,
- “odwrotne zredukowanie” (odjęcie) wartości które opuściły już okno
import re
from pyspark import SparkContext
from pyspark.streaming import StreamingContext
sc = SparkContext("local[2]", "NetworkWC4")
ssc = StreamingContext(sc, 2)
ssc.checkpoint("tmp")
lines = ssc.socketTextStream("localhost", 9999)
words = lines.flatMap(lambda x: re.findall(r"[a-z']+", x.lower()))
pairs = words.map(lambda word: (word,1))
windowedWordCounts = pairs.reduceByKeyAndWindow(lambda x, y: x + y, lambda x, y: x - y, 30, 10)
windowedWordCounts.pprint()
ssc.start()
ssc.awaitTermination()
ssc.stop(True,True)