Analiza Danych w czasie rzeczywistym kurs dla studentów SGH
Ćwiczenia 6 - Apache Kafka
Distributed Stream Processing System
Wielo-serwerowa platforma do propagacji zdarzeń w rozproszonych systemach informatycznych. Stworzona na potrzeby LinkedIn w 2011 roku (napisana w Scala i Java). Obecnie zarządzana przez Apache Foundation. Cechuje się znakomitą skalowalnością horyzontalną. Pozwala na budowanie systemów (na klastrach) potrafiących propagować setki tysięcy zdarzeń dziennie.
Do największych firm pracujących na Kafce należą: LinkedIn, Oracle, PayPal, Uber, Yahoo, Trivago, Twitter, Spotify, Skyscanner, Cisco, AirBnB, Adidas, Zalando czy Netflix.
Kluczową cechą i podstawową funkcjonalnością tej technologii jest możliwość publikowania (za pomocą tzw. producentów) różnego rodzaj zdarzeń. Zdarzenia te następnie mogą zostać pobrane przez jednego (lub wielu) tzw. konsumentów.
Jeśli nic z tego nie rozumiesz wyobraź sobie prostą sytuację:
Nagrywasz video z kursem, który chcesz udostępniać. Jak możesz je rozprowadzać?
- możesz nagrać je na dvd i wysyłać do odbiorców (którzy o to poproszą i dadzą adres)
- możesz załączyć video (to chyba nie za duży film) do wiadomości email (tutaj również potrzebujesz zapytania, zgody no i … adresu email).
Teraz wyobraź sobie, że jednak wrzucasz film na YouTube - bądź inną platformę Brokerską. W tym momencie jesteś już Producentem (jednym z tysięcy). Produkujesz swoje źródła i kontent wrzucasz na platformę. Treść może być przechowywana na jakiejś bazie. Platforma ta wykorzystywana jest przez setki tysięcy użytkowników (Konsumentów) by odtwarzać zawartość wtedy kiedy mają na to chęć. Nie potrzebujesz znać ani ich adresu email, ani fizycznego adresu na który musisz wysłać film. Platforma działa jako broker. Przechowuje setki tysięcy rzeczy produkowanych przez Producentów (push data) i udostępnia każdemu, kto wyśle zapytanie pobierające (pull data). Zauważ, że jedno źródło może być przetwarzane przez wielu konsumentów na raz. Również jeden producent może generować dane o wielu tematach.
Poszukaj info i przykład Data Driven vs Event Driven Apps
Instalacja i weryfikacja
- Przejdź na stronę Kafki. Aktualna wersja stabilna
2.8.0. - Ściągnij plik z Binary downloads (wersja 2.12) i rozpakuj programem 7-zip . Uwaga w systemie Win rozpakuj również archiwum tar.
- Zmień nazwę katalogu na kafka i wrzuć go do przyjaznej lokalizacji (np na pulpit)
- W przypadku systemu Win przejdź do katalogu config i znajdź plik server.properties. Otwórz go w dowolnym edytorze i znajdź linie odpowiedzialną za ustawienie katalogu z logami. Ustaw katalog w swojej dogodnej lokalizacji. np.
C:\\Users\\szajac2\\Desktop\\kafka\\logs
- Uruchom serwer zookeepera
bin/zookeeper-server-start.sh config/zookeeper.propertieslub
bin\windows\zookeeper-server-start.bat config\zookeeper.properties - uruchom serwer Kafki
bin/kafka-server-start.sh config/server.propertieslub
bin\windows\kafka-server-start.bat config\server.properties - Stwórz topic i uruchom producenta i konsumenta w osobnych konsolach.
Zamiast kroków 5 i 6 możesz uruchomić dockera obraz RTA KAFKA
docker-compose up
Kafka udostępnia API praktycznie we wszystkich istotnych językach programowania. Dla nas istotne jest API Pythona.
Broker
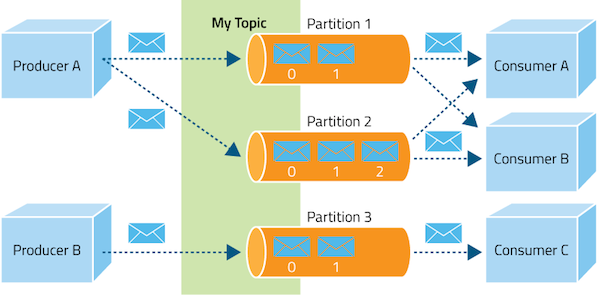
Brokerem nazywamy pojedynczą aplikację Kafki (serwer). Podczas działania całej struktury można uruchomić wiele brokerów. Dystrybucja wiadomości jest podzielona na partycje. Partycje pozwalają na replikacje topików i przydają się podczas awarii któregoś z serwera. Jednostki opisywane są jako liderzy i followerzy.
zookeeper
Apache zookeeper to scentralizowana usługa wymagana do działania Kafki. Zajmuje się konfiguracją topików, kontrolą brokerów. Pozwala wyznaczyć ich statusy i metryki.
Kafka Topic (temat)
Temat to abstrakcja do której można publikować zdarzenia. Kafka umożliwia przetwarzanie wielu tematów w jednym systemie. Ponadto każdy temat może być obsługiwany przez wielu konsumentów pobierających zdarzenia z konkretnych tematów. Dla każdego tematu utrzymywany jest rozproszony log, w którym zapisywane są opublikowane zdarzenia. Logi zawarte na partycjach są uporządkowane czasowo i niezmienialne. Można tylko dopisywać nowe zdarzenia. Wszystkie dane przechowywane są przez określony (konfigurowalny - domyślnie 7 dni) okres czasu (retention time). Jeśli konsument nie odczyta danych do tego czasu traci możliwość jego przetworzenia. Ustawienie długiego czasu wpływa tylko i wyłącznie na ilość zużytego miejsca na dysku. Każde zdarzenie reprezentowane jest jako para ‘klucz’:’wartość’. Przy czym sam broker (platforma) jest pasywna - nie tworzy nowych eventów. Dane mogą pochodzić tylko od producentów a ich przetwarzaniem zajmują się tylko konsumenci.
Topic odpowiada w przetwarzaniu danych pojęciu tabeli.
Message odpowiada w przetwarzaniu danych pojęciu wiersza.
Partition odpowiada w przetwarzaniu danych pojęciu widoku.
Kafka Connect - zbiór gotowych adapterów pozwalających tworzyć zdarzenia na podstawie danych znajdujących się w rozwiązaniach służących do przechowywania lub przetwarzania danych tj. Active MQ, Amazon S3, ElasticSearch, Cassandra, MySQL, PostgresSQL, SQLServer czy MongoDB. Adaptery te pozwalająca zarówno na pobieranie danych jak i ich zapis.
Kafka Stream - rozwiązanie pozwalające na transformację zdarzeń wewnątrz platformy. Wykorzystuje język zapytań KSQL pozwalając na wykonywanie skalowalnych i elastycznych zapytań na strumieniach danych. Najczęściej wykorzystywane do normalizacji danych przychodzących z różnych źródeł.
Producent w konsoli
bin/kafka-console-producer.sh --topic rta --bootstrap-server localhost:9092
Konsumer w konsoli
bin/kafka-console-consumer.sh --topic rta --bootstrap-server localhost:9092 --from-beginning
Producent w bibliotece Pythona
topic = 'rta'
from kafka import KafkaProducer
producer = KafkaProducer(bootstrap_servers=['127.0.0.1:9092"])
producer.send(topic, b'testowy tekst ')
pr = KafkaProducer(bootstrap_servers=['localhost:9092'], value_serializer=lambda x: json.dumps(x).encode('utf-8'))
pr.send(topic, {"id":1, "imie":"adam","nazwisko":"nowak"})
# wersja z jsonem