W przypadku obliczeń (kwantowych) hybrydowe oznacza strategię mieszania klasycznych i kwantowych obliczeń. Idea ta jest podstawowym elementem optymalizacji obwodów wariacyjnych, gdzie kwantowy obwód optymalizowany jest z wykorzystaniem klasycznego ko-procesora.
Najczęściej, obwody (i komputery) kwantowe będziemy wykorzystywać do oszacowania (obliczania) średnich z wyników pomiarów (wartość oczekiwana obserwabli), które złozyć mozna do pojedynczej klasycznej funkcji kosztu. Pozwola nam to oszacować jak dobrze wybrane obwody kwantowe dopasowują się do danych. Przykładem moze być model realizowany jako variational quantum eigensolverPeruzzo 2013
W ogólności łatwo wyobrazić sobie bardziej interesujący sposób w którym mozna łączyć składniki klasyczne i kwantowe w większy i bardziej złozony układ Kazdy element (czy to kwantowy czy klasyczny) mozna w takim obrazku przedstawić jako klasyczny bądź kwantowy node.
Klasyczne i kwantowe nody mozemy składać w dowolny acykliczny graf (DAG). Informacja w takim grafie przebiega w ustalonym kierunku oraz nie występują w nim cykle (pętle).
Jednym z przykładów takiego DAG’a są sieci neuronowe.
Poniewaz mozemy obliczać gradienty variacyjnych obwodów kwantowych, obliczenia hybrydowe są kompatybilne z algorytmem propagacji wstecznej. Potwierdza to możliwość trenowania obwodów kwantowych w taki sam sposób w jaki trenuje sie klasyczne sieci neuronowe.
Korzystając z biblioteki PyTorch możemy generować sieci neuronowe korzystając z modułu nn. Każdy taki model składa się z elementarnych warstw (ang. layers). Bilioteka PennyLane pozwala przetworzyć obiekt QNode do obiektu torch.nn.
W pierwszym kroku stwórzmy dwa zestawy danych. Pierwszy dotyczyć będzie wartości ciągłej, natomiast drugi będzie realizował proces klasyfikacji.
Dane muszą być przekształcone do obiektu tensora realizowanego w bibliotece torch.
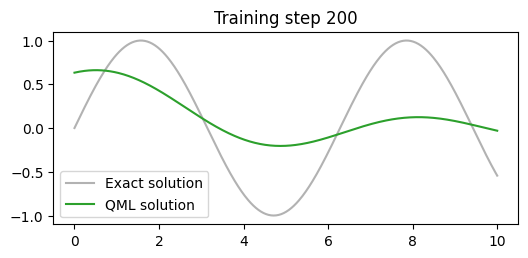
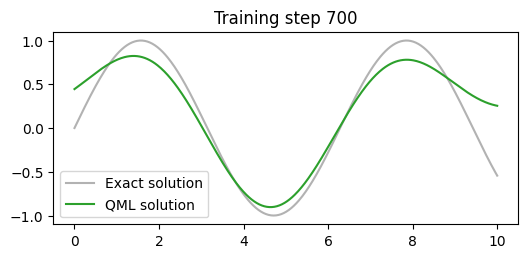
# DANE dla przewidywania zmiennej ciągłej - funkcja sinus z drobnym szumemimport torchtorch.manual_seed(123)X_cont = torch.linspace(0,10,500).view(-1,1)y_cont = torch.sin(X_cont)y_cont_noise = y_cont +0.1*(torch.rand(500).view(-1,1)-0.5)# wyktres danychimport matplotlib.pyplot as pltplt.figure(figsize=(8,4))plt.plot(X_cont, y_cont.view(-1,1), color="tab:grey", alpha=0.6, label="dokładne rozwiązanie")plt.scatter(X_cont, y_cont_noise, label="dane treningowe")plt.axis("off")plt.legend()plt.show()
Zanim przejdziemy do daleszego etapy zdefiniujmy dodatkowe funkcje przydatne do eksploracji sieci neuronowych.
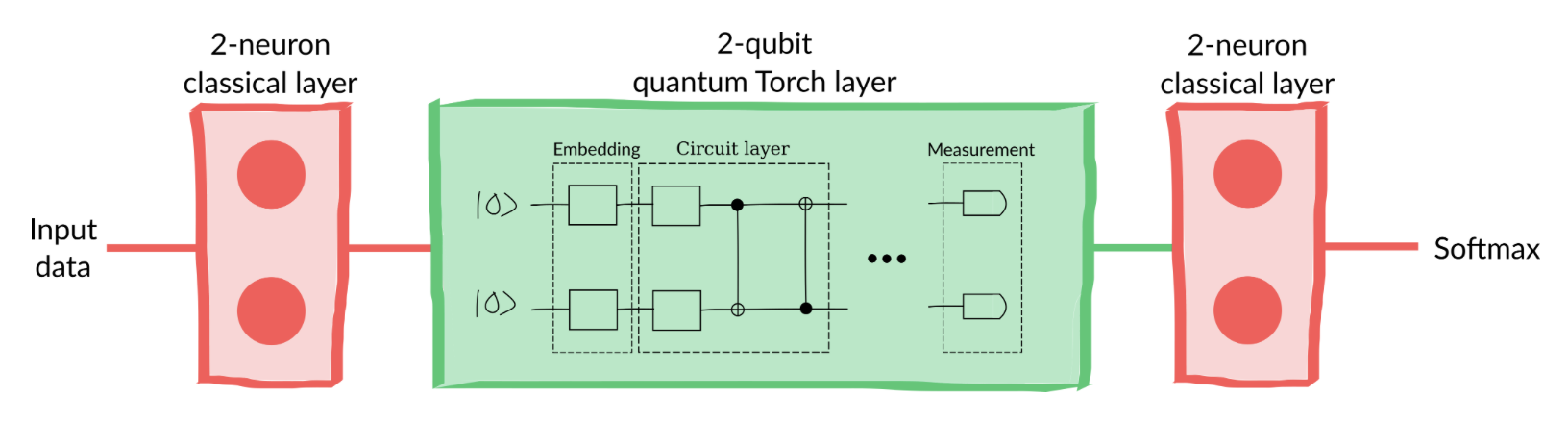
W następnym kroku zdefiniujmy obiekt realizujący obwód kwantowy: QNode, który chcemy podpiąć pod torch.nn. Dla uproszczenia sytuacji przyjmiemy obwód wykorzystujący 2 kubity.
import pennylane as qmln_qubits =2dev = qml.device("default.qubit", wires=n_qubits)# NASZ kwantowy PQC - parametryzowany obwód kwantowy dla jednej warstwy ukrytej@qml.qnode(dev)def qnode(inputs, weights): qml.AngleEmbedding(inputs, wires=range(n_qubits)) qml.BasicEntanglerLayers(weights, wires=range(n_qubits))return [qml.expval(qml.PauliZ(wires=i)) for i inrange(n_qubits)]
Obwód ten pobiera dane wejściowe i przetwarza je za pomocą zdefiniowanego obwodu kodującego dane Angle Embedding. Następnie wynik tej operacji,czyli dane zanurzone do przestrzeni Hilberta stanów, są przetwarzane (obracane przez parametryczne bramki z wagami) jest przez ansatz (model kwantowy) z wykorzystaniem gotowego obwodu realizowanego jako BasicENtanglerLayers.
Całość można zrozumieć jako jedna wartwa nn.Linear.
Biblioteka PennyLane udostępnia obiekt TorchLayer, który pozwala na taką transformację. Zanim jednak go użyjemy musimy utworzyć słownik z wagami.
Dla przypadku estymacji funkcji sinus mamy jedną zmienną (x_cont) wejściową która zostanie połączona z dwoma kubitami następnie na wyjściu mamy również jedną zmienną (y_cont).
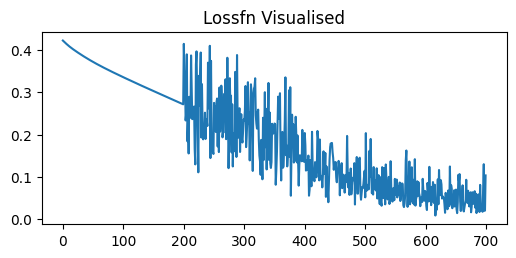
Average loss over epoch 1: 0.4803
Average loss over epoch 2: 0.3293
Average loss over epoch 3: 0.2266
Average loss over epoch 4: 0.1889
Average loss over epoch 5: 0.1809
Average loss over epoch 6: 0.1726
Accuracy: 86.5%
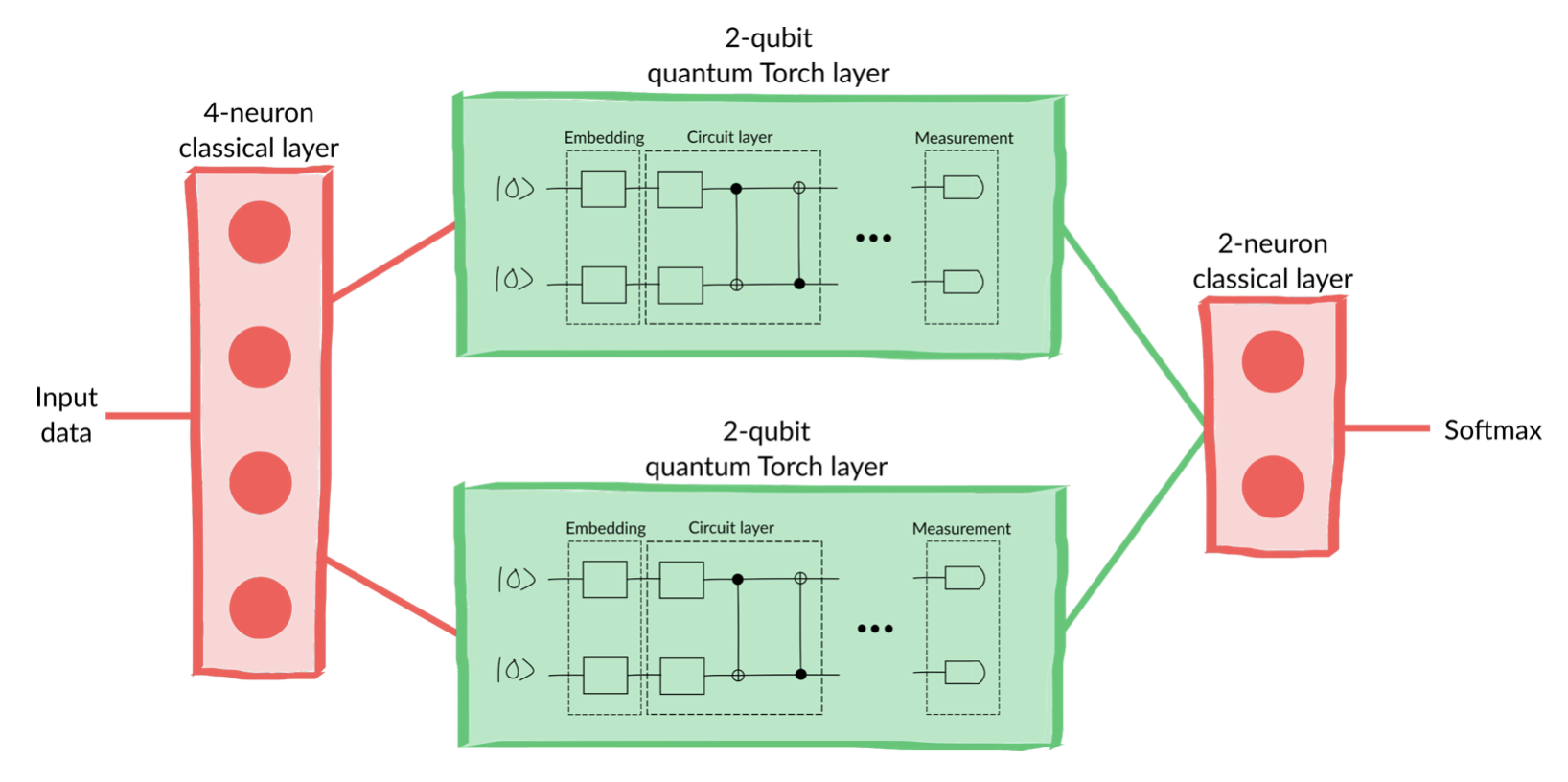
class HybridModel(torch.nn.Module):def__init__(self):super().__init__()self.clayer_1 = torch.nn.Linear(2, 4)self.qlayer_1 = qml.qnn.TorchLayer(qnode, weight_shapes)self.qlayer_2 = qml.qnn.TorchLayer(qnode, weight_shapes)self.clayer_2 = torch.nn.Linear(4, 2)self.softmax = torch.nn.Softmax(dim=1)def forward(self, x): x =self.clayer_1(x) x_1, x_2 = torch.split(x, 2, dim=1) x_1 =self.qlayer_1(x_1) x_2 =self.qlayer_2(x_2) x = torch.cat([x_1, x_2], axis=1) x =self.clayer_2(x)returnself.softmax(x)model = HybridModel()
Average loss over epoch 1: 0.4345
Average loss over epoch 2: 0.2538
Average loss over epoch 3: 0.1893
Average loss over epoch 4: 0.1633
Average loss over epoch 5: 0.1664
Average loss over epoch 6: 0.1548
Accuracy: 87.0%