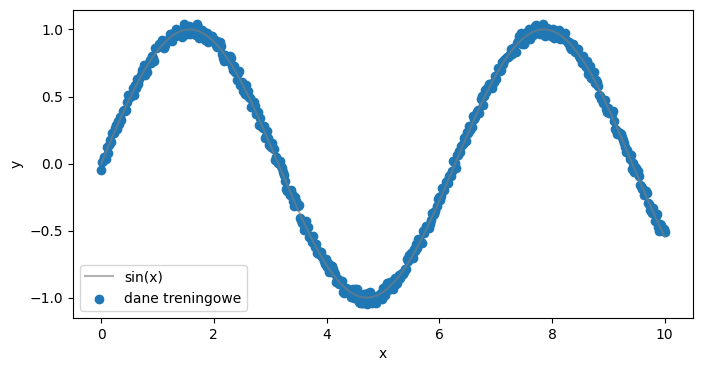
class SinusEstimator(torch.nn.Module):
def __init__(self, N_INPUT: int, N_OUTPUT: int):
super(SinusEstimator,self).__init__()
self.layers = torch.nn.Sequential(
torch.nn.Linear(N_INPUT, 64),
torch.nn.ReLU(),
torch.nn.Linear(64,32),
torch.nn.ReLU(),
torch.nn.Linear(32,16),
torch.nn.Tanh(),
torch.nn.Linear(16,N_OUTPUT)
)
def forward(self, x):
x = self.layers(x)
return x
model = SinusEstimator(1,1)
learning_rate=0.001
optimiser = torch.optim.Adam(model.parameters(), lr=learning_rate)
criterion = torch.nn.MSELoss()
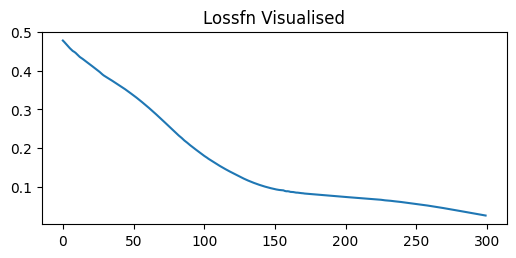
losses = []
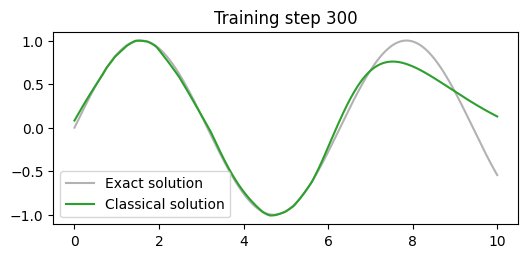
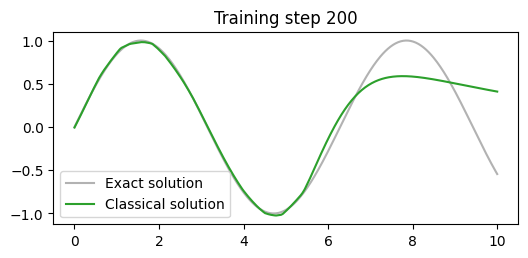
def callback(model, loss):
losses.append(loss.item())
clear_output(wait=True)
prediction = model(x).detach()
plt.figure(figsize=(6,2.5))
plt.plot(x[:,0].detach(), torch.sin(x)[:,0].detach(), label="Exact solution", color="tab:grey", alpha=0.6)
plt.plot(x[:,0].detach(), prediction[:,0], label="Classical solution", color="tab:green")
plt.title(f"Training step {len(losses)}")
plt.legend()
plt.show()
plt.figure(figsize=(6,2.5))
plt.title('Lossfn Visualised')
plt.plot(losses)
plt.show()
def train(X,Y, model, optimiser, epochs, lossfn, callback = None):
for epoch in range(epochs):
model.train()
prediction = model(X)
loss = lossfn(prediction, Y)
optimiser.zero_grad()
loss.backward()
optimiser.step()
model.eval()
if callback != None:
callback(model, loss)
x_train = x.requires_grad_(True)
train(x_train, y, model, optimiser, 300, criterion, callback)