---
title: "Wykład 2 — Batch vs Stream. Architektury Lambda i Kappa"
subtitle: "Analiza danych w czasie rzeczywistym"
description: "Przetwarzanie wsadowe vs strumieniowe, architektury Lambda i Kappa, czas zdarzenia, watermarking i okna czasowe."
format:
html:
code-fold: true
code-tools: true
code-summary: "Pokaż kod"
toc: true
toc-depth: 3
toc-title: "Spis treści"
number-sections: true
smooth-scroll: true
theme:
light: flatly
highlight-style: github
fig-align: center
fig-cap-location: bottom
jupyter: python3
---
::: {.callout-note appearance="minimal"}
## Czas trwania: 1,5h
**Cel wykładu:** Zrozumienie różnic między przetwarzaniem wsadowym a strumieniowym, poznanie architektur Lambda i Kappa, oraz kluczowych pojęć: czas zdarzenia, czas przetwarzania, okna czasowe.
:::
---
## Batch vs Stream — dwa podejścia do tych samych danych
Na poprzednim wykładzie ustaliliśmy, że dane **zawsze** powstają jako strumień zdarzeń. Przetwarzanie wsadowe to tylko uproszczenie — zbieramy strumień do pliku i analizujemy z opóźnieniem.
Porównajmy oba podejścia na tym samym problemie biznesowym: **monitorowanie transakcji w sklepie internetowym**.
::: {.panel-tabset}
### {{< fa database >}} Podejście wsadowe (batch)
```{python}
import pandas as pd
import numpy as np
from datetime import datetime, timedelta
np.random.seed(42)
# Dane zebrane z całego dnia — analizowane następnego ranka
transakcje = pd.DataFrame({
'czas': [datetime(2026, 3, 12, h, m)
for h in range(9, 18)
for m in np.random.choice(range(60), 20)],
'kwota': np.random.uniform(20, 3000, 180).round(2),
'klient_id': np.random.randint(1000, 9999, 180)
})
# Raport dzienny — widzimy go NASTĘPNEGO DNIA
raport = transakcje.groupby(transakcje['czas'].dt.hour).agg(
liczba=('kwota', 'count'),
suma=('kwota', 'sum'),
srednia=('kwota', 'mean')
).round(2)
print("Raport dzienny (generowany następnego ranka):")
print(raport.head())
```
### {{< fa bolt >}} Podejście strumieniowe (stream)
```{python}
import time
# Symulacja: każda transakcja analizowana w momencie pojawienia się
okno_5min = []
alert_prog = 5000 # alert jeśli suma w oknie 5min > 5000 PLN
for i in range(10):
tx = {
'czas': datetime.now().strftime('%H:%M:%S'),
'kwota': round(np.random.uniform(20, 3000), 2),
'klient': np.random.randint(1000, 9999)
}
okno_5min.append(tx['kwota'])
suma_okno = sum(okno_5min)
status = ""
if suma_okno > alert_prog:
status = " << ALERT: wysoka aktywność!"
okno_5min = [] # reset okna
print(f"[{tx['czas']}] Klient {tx['klient']}: {tx['kwota']:>8.2f} PLN | Suma okna: {suma_okno:>9.2f}{status}")
time.sleep(0.2)
```
:::
::: {.callout-important}
## Fundamentalna różnica
W trybie batch dowiadujemy się o problemie **następnego dnia**. W trybie stream — **natychmiast**.
:::
---
## Architektura Lambda
W praktyce firmy potrzebują **obu** podejść jednocześnie. Architektura Lambda, zaproponowana przez Nathana Marza, łączy przetwarzanie wsadowe i strumieniowe w jednym systemie.
### Trzy warstwy Lambdy
:::: {.columns}
::: {.column width="33%"}
::: {.callout-note appearance="simple"}
## {{< fa database >}} Warstwa wsadowa
**Batch Layer** — przetwarza kompletny zbiór danych w regularnych interwałach. Daje dokładne wyniki, ale z opóźnieniem.
*Narzędzia:* Spark (batch), Hadoop
:::
:::
::: {.column width="33%"}
::: {.callout-warning appearance="simple"}
## {{< fa bolt >}} Warstwa szybka
**Speed Layer** — przetwarza dane strumieniowe w czasie rzeczywistym. Daje przybliżone wyniki, ale natychmiast.
*Narzędzia:* Spark Streaming, Kafka Streams
:::
:::
::: {.column width="33%"}
::: {.callout-tip appearance="simple"}
## {{< fa server >}} Warstwa serwująca
**Serving Layer** — łączy wyniki z obu warstw i udostępnia je użytkownikom końcowym.
*Narzędzia:* bazy danych, API, dashboardy
:::
:::
::::
```{mermaid}
%%| fig-cap: "Architektura Lambda"
flowchart TD
SRC["Źródło danych\n(strumień zdarzeń)"] --> BATCH["Warstwa wsadowa\n(Batch Layer)\nKompletne dane\nDuże opóźnienie"]
SRC --> SPEED["Warstwa szybka\n(Speed Layer)\nNajnowsze dane\nNiska latencja"]
BATCH --> SERVE["Warstwa serwująca\n(Serving Layer)\nDashboard / API"]
SPEED --> SERVE
style BATCH fill:#2196F3,color:#fff
style SPEED fill:#F44336,color:#fff
style SERVE fill:#4CAF50,color:#fff
```
::: {.callout-tip collapse="true"}
## {{< fa building-columns >}} Przykład biznesowy: Bank analizujący transakcje kartowe
- **Warstwa wsadowa:** co noc przelicza historyczne wzorce zachowań klientów, trenuje modele fraud detection.
- **Warstwa szybka:** w czasie rzeczywistym porównuje każdą transakcję z wzorcami i blokuje podejrzane operacje.
- **Warstwa serwująca:** dashboard dla analityków + API dla aplikacji mobilnej.
:::
### Zalety i wady Lambdy
**Zaleta:** kompletność — batch layer koryguje błędy speed layer.
::: {.callout-caution}
## Główna wada Lambdy
Utrzymujesz **dwie oddzielne ścieżki przetwarzania** — dwa kody, dwa zestawy testów, dwa środowiska. To jest kosztowne i podatne na błędy.
:::
---
## Architektura Kappa
Jay Kreps (twórca Apache Kafka) zaproponował uproszczenie: **a co, gdyby potrzebna była tylko warstwa strumieniowa?**
Architektura Kappa to Lambda bez warstwy wsadowej. Cały przepływ danych opiera się na strumieniu zdarzeń. Jeśli trzeba przeliczyć dane historyczne — odtwarzamy strumień od początku (replay).
```{mermaid}
%%| fig-cap: "Architektura Kappa — uproszczenie Lambdy"
flowchart TD
SRC["Źródło danych\n(strumień zdarzeń)"] --> STREAM["Warstwa strumieniowa\n(Stream Layer)\nJeden kod, jeden pipeline"]
STREAM --> SERVE["Warstwa serwująca\nDashboard / API"]
STREAM -.->|replay| SRC
style STREAM fill:#FF9800,color:#fff
style SERVE fill:#4CAF50,color:#fff
```
### Lambda vs Kappa — kiedy co stosować?
| Cecha | {{< fa layer-group >}} Lambda | {{< fa arrows-turn-right >}} Kappa |
|-------|--------|-------|
| Złożoność | Wysoka (dwie ścieżki) | Niska (jedna ścieżka) |
| Dokładność | Batch koryguje stream | Zależna od jakości streamingu |
| Historyczne przeliczanie | Naturalne (batch) | Replay strumienia |
| Kiedy stosować | Gdy batch i stream mają różną logikę | Gdy jedna logika wystarcza |
| Przykład | Bank (nocne retrenowanie + RT scoring) | E-commerce (personalizacja) |
: Lambda vs Kappa {.striped .hover}
---
## Czas w przetwarzaniu strumieniowym
W przetwarzaniu wsadowym czas nie jest problemem — analizujemy dane historyczne, kiedy chcemy. W przetwarzaniu strumieniowym czas staje się **kluczowym wymiarem analizy**.
### Dwa rodzaje czasu
:::: {.columns}
::: {.column width="50%"}
::: {.callout-note appearance="simple"}
## {{< fa calendar-day >}} Czas zdarzenia (event time)
Moment, w którym zdarzenie **faktycznie nastąpiło**.
*Np. klient kliknął „Kup" o 14:23:45.*
:::
:::
::: {.column width="50%"}
::: {.callout-warning appearance="simple"}
## {{< fa server >}} Czas przetwarzania (processing time)
Moment, w którym system **odebrał i przetworzył** zdarzenie.
*Np. system Kafki odebrał zdarzenie o 14:23:47.*
:::
:::
::::
W idealnym świecie oba czasy byłyby identyczne. W praktyce zawsze istnieje **opóźnienie** (latency) — spowodowane siecią, buforowaniem, awarią urządzeń.
```{python}
# Symulacja: zdarzenia docierają z losowym opóźnieniem
import random
zdarzenia = []
for i in range(8):
event_time = datetime(2026, 3, 12, 14, 23, i * 2) # co 2 sekundy
delay = random.uniform(0.1, 5.0) # opóźnienie 0.1–5s
processing_time = event_time + timedelta(seconds=delay)
zdarzenia.append({
'event_time': event_time.strftime('%H:%M:%S'),
'processing_time': processing_time.strftime('%H:%M:%S.') + f'{int(delay*100):02d}',
'opóźnienie': f'{delay:.1f}s'
})
df = pd.DataFrame(zdarzenia)
print(df.to_string(index=False))
```
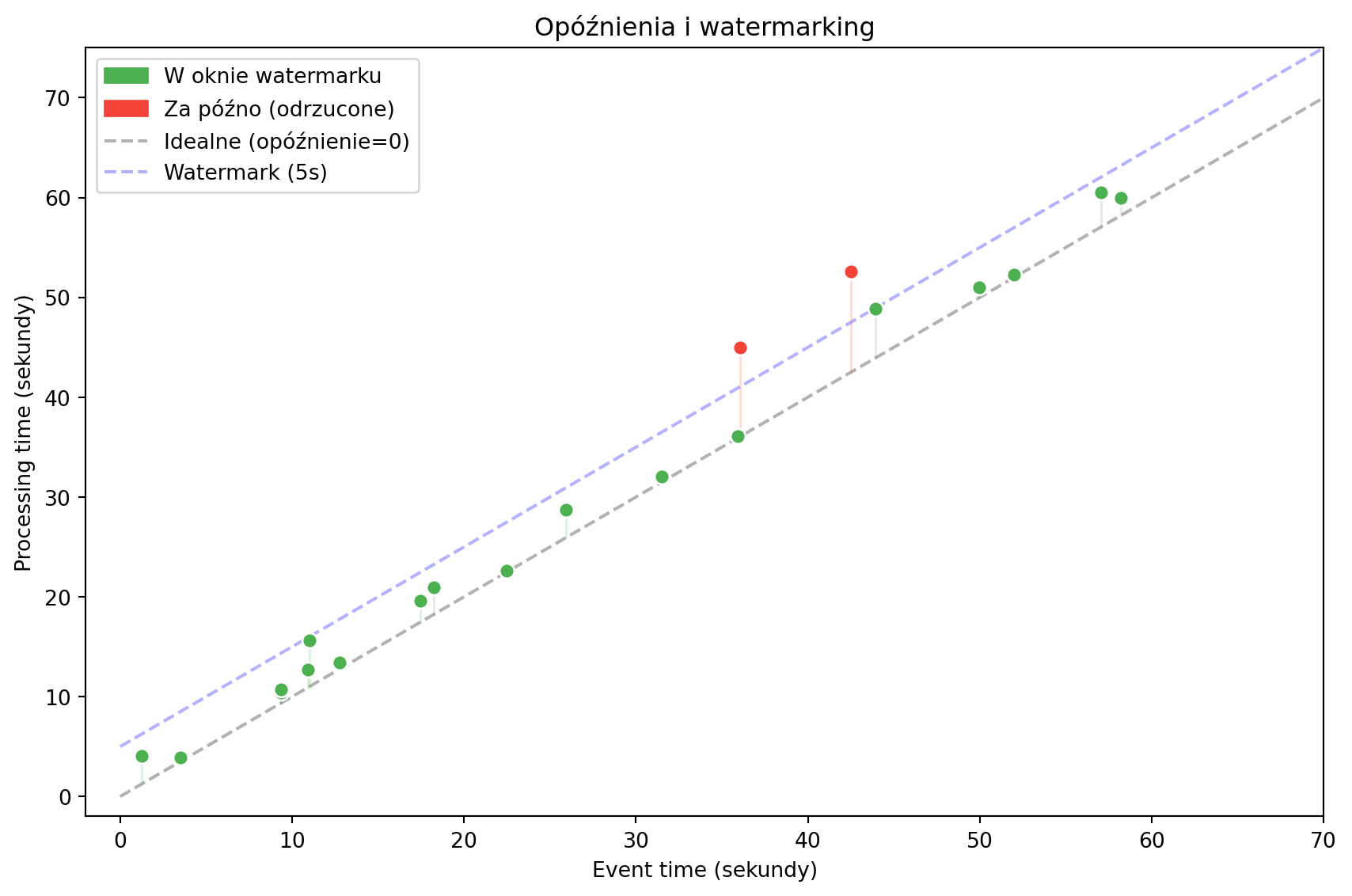
```{python}
#| label: fig-event-vs-processing
#| fig-cap: "Czas zdarzenia vs czas przetwarzania — opóźnienia w systemach strumieniowych"
import matplotlib.pyplot as plt
import matplotlib.patches as mpatches
np.random.seed(42)
n = 20
evt = np.sort(np.random.uniform(0, 60, n))
delays = np.random.exponential(3, n)
proc = evt + delays
watermark = 5
fig, ax = plt.subplots(figsize=(9, 6))
ax.plot([0, 70], [0, 70], 'k--', alpha=0.3, label='Idealne (opóźnienie=0)')
ax.plot([0, 70], [watermark, 70+watermark], 'b--', alpha=0.3, label=f'Watermark ({watermark}s)')
for i in range(n):
in_wm = proc[i] <= evt[i] + watermark + 1
color = '#4CAF50' if in_wm else '#F44336'
ax.scatter(evt[i], proc[i], c=color, s=50, zorder=5, edgecolors='white')
ax.plot([evt[i], evt[i]], [evt[i], proc[i]], color=color, alpha=0.2, linewidth=1)
gp = mpatches.Patch(color='#4CAF50', label='W oknie watermarku')
rp = mpatches.Patch(color='#F44336', label='Za późno (odrzucone)')
ax.legend(handles=[gp, rp, ax.lines[0], ax.lines[1]], loc='upper left')
ax.set_xlabel('Event time (sekundy)')
ax.set_ylabel('Processing time (sekundy)')
ax.set_title('Opóźnienia i watermarking')
ax.set_xlim(-2, 70)
ax.set_ylim(-2, 75)
plt.tight_layout()
plt.show()
```
::: {.callout-tip collapse="true"}
## {{< fa car >}} Analogia: GPS w tunelu
Wyobraź sobie śledzenie samochodu przez GPS. Pojazd wjeżdża w tunel — przez 30 sekund nie ma sygnału. Po wyjściu z tunelu urządzenie wysyła naraz 30 odczytów. System musi wiedzieć, że te zdarzenia dotyczą **przeszłości**, a nie teraźniejszości.
:::
Opóźnione zdarzenia możemy obsłużyć na dwa sposoby:
- **Ignorowanie** — odrzucamy zdarzenia, które przyszły zbyt późno (ryzyko utraty danych).
- **Watermarking** — definiujemy „znacznik wodny" — maksymalne dopuszczalne opóźnienie. Zdarzenia, które mieszczą się w oknie watermarku, są uwzględniane. Reszta odrzucana.
---
## Okna czasowe
W przetwarzaniu strumieniowym nie możemy analizować „wszystkich danych" — strumień jest nieskończony. Zamiast tego grupujemy zdarzenia w **okna czasowe** o skończonej długości.
::: {.panel-tabset}
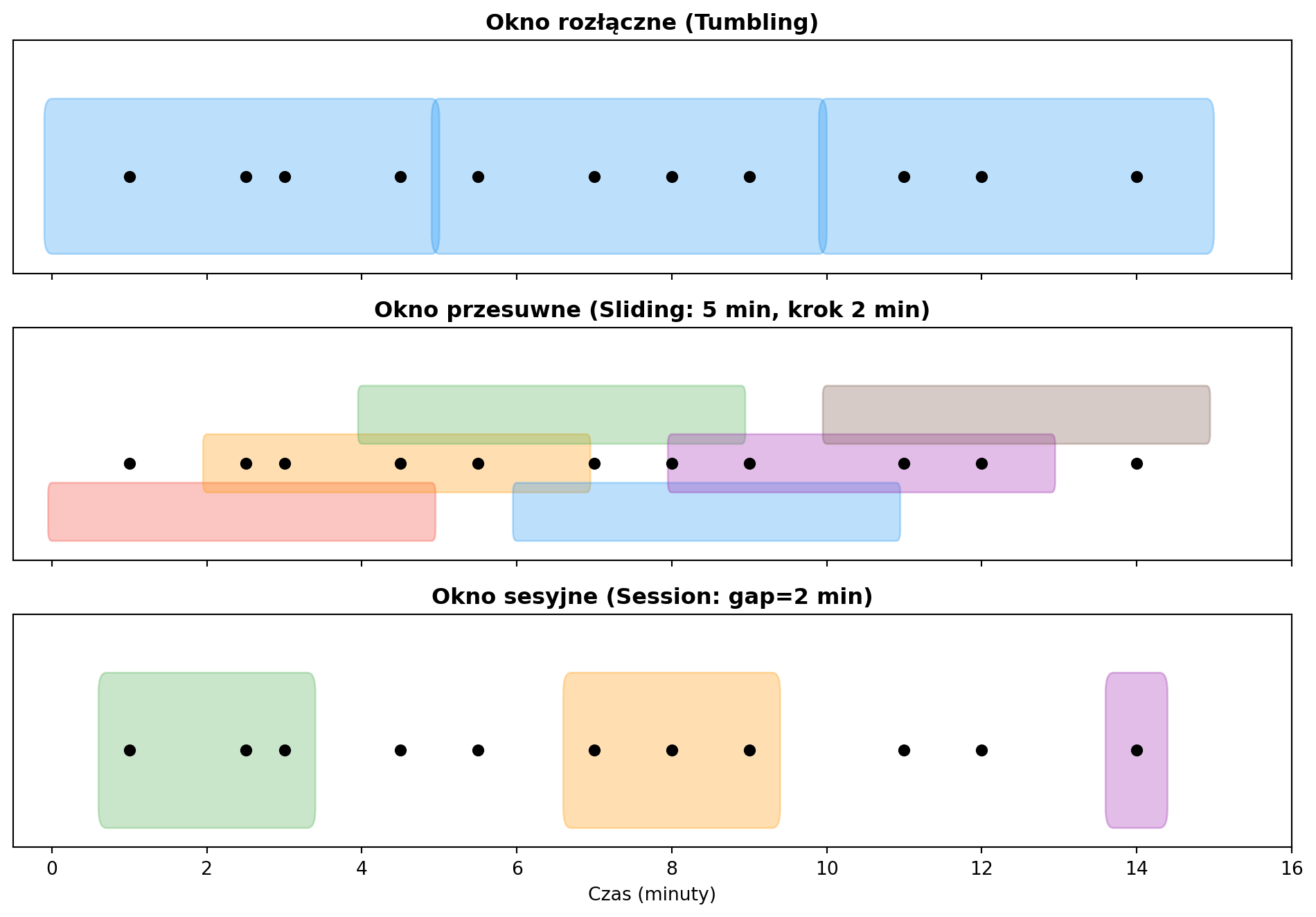
### Rozłączne (Tumbling)
Stała długość, brak nakładania. Każde zdarzenie należy do **dokładnie jednego** okna.
*Przykład:* suma transakcji co 5 minut.
```{python}
# Symulacja okna rozłącznego (tumbling) 5-minutowego
np.random.seed(42)
zdarzenia = pd.DataFrame({
'czas': pd.date_range('2026-03-12 14:00', periods=30, freq='30s'),
'kwota': np.random.uniform(10, 500, 30).round(2)
})
# Tumbling window: grupowanie co 5 minut
zdarzenia['okno'] = zdarzenia['czas'].dt.floor('5min')
wynik = zdarzenia.groupby('okno')['kwota'].agg(['sum', 'count']).round(2)
wynik.columns = ['suma', 'liczba']
print("Okno rozłączne (5 min):")
print(wynik)
```
### Przesuwne (Sliding)
Stała długość, ale okno przesuwa się o zadany interwał — zdarzenia mogą należeć do **wielu okien**.
*Przykład:* średnia z ostatnich 10 minut, aktualizowana co 2 minuty. Przydatne do wykrywania trendów.
### Skokowe (Hopping)
Podobne do sliding, ale z możliwością nakładania się okien o określony krok. Stosowane do wygładzania danych.
### Sesyjne (Session)
Dynamiczna długość — okno trwa tak długo, jak długo przychodzą zdarzenia. Zamyka się po określonym czasie braku aktywności (**gap**).
*Przykład:* sesja użytkownika na stronie internetowej. Sesja trwa, dopóki użytkownik klika. Kończy się po 15 minutach braku aktywności.
:::
### Porównanie okien
| Typ okna | Długość | Nakładanie | Zastosowanie |
|----------|---------|:----------:|-------------|
| Rozłączne (Tumbling) | Stała | {{< fa xmark >}} | Raporty okresowe |
| Przesuwne (Sliding) | Stała | {{< fa check >}} | Wykrywanie trendów |
| Skokowe (Hopping) | Stała | Częściowe | Wygładzanie danych |
| Sesyjne (Session) | Dynamiczna | {{< fa xmark >}} | Analiza sesji użytkowników |
: Typy okien czasowych {.striped .hover}
```{python}
#| label: fig-window-types
#| fig-cap: "Typy okien czasowych — wizualizacja"
import matplotlib.pyplot as plt
import matplotlib.patches as mpatches
fig, axes = plt.subplots(3, 1, figsize=(10, 7), sharex=True)
events_x = [1, 2.5, 3, 4.5, 5.5, 7, 8, 9, 11, 12, 14]
# Tumbling
ax = axes[0]
ax.set_title('Okno rozłączne (Tumbling)', fontweight='bold')
for start in range(0, 15, 5):
rect = mpatches.FancyBboxPatch((start, 0.2), 4.9, 0.6, boxstyle="round,pad=0.1",
facecolor='#2196F3', alpha=0.3, edgecolor='#2196F3')
ax.add_patch(rect)
ax.scatter(events_x, [0.5]*len(events_x), c='black', s=30, zorder=5)
ax.set_ylim(0, 1.2)
ax.set_yticks([])
# Sliding
ax = axes[1]
ax.set_title('Okno przesuwne (Sliding: 5 min, krok 2 min)', fontweight='bold')
colors = ['#F44336', '#FF9800', '#4CAF50', '#2196F3', '#9C27B0', '#795548', '#607D8B']
for i, start in enumerate(range(0, 12, 2)):
y_offset = 0.15 + (i % 3) * 0.25
rect = mpatches.FancyBboxPatch((start, y_offset), 4.9, 0.2, boxstyle="round,pad=0.05",
facecolor=colors[i % len(colors)], alpha=0.3, edgecolor=colors[i % len(colors)])
ax.add_patch(rect)
ax.scatter(events_x, [0.5]*len(events_x), c='black', s=30, zorder=5)
ax.set_ylim(0, 1.2)
ax.set_yticks([])
# Session
ax = axes[2]
ax.set_title('Okno sesyjne (Session: gap=2 min)', fontweight='bold')
session_events = [[1, 2.5, 3], [7, 8, 9], [14]]
sess_colors = ['#4CAF50', '#FF9800', '#9C27B0']
for j, (sess, col) in enumerate(zip(session_events, sess_colors)):
start = min(sess) - 0.3
end = max(sess) + 0.3
rect = mpatches.FancyBboxPatch((start, 0.2), end-start, 0.6, boxstyle="round,pad=0.1",
facecolor=col, alpha=0.3, edgecolor=col)
ax.add_patch(rect)
ax.scatter(events_x, [0.5]*len(events_x), c='black', s=30, zorder=5)
ax.set_ylim(0, 1.2)
ax.set_yticks([])
ax.set_xlabel('Czas (minuty)')
ax.set_xlim(-0.5, 16)
plt.tight_layout()
plt.show()
```
```{python}
# Porównanie: tumbling vs sliding window na tych samych danych
print("=== Tumbling (5 min) ===")
tumbling = zdarzenia.groupby(zdarzenia['czas'].dt.floor('5min'))['kwota'].sum().round(2)
print(tumbling)
print("\n=== Sliding (okno 5 min, krok 1 min) ===")
for start_min in range(0, 15, 1):
start = pd.Timestamp('2026-03-12 14:00') + pd.Timedelta(minutes=start_min)
end = start + pd.Timedelta(minutes=5)
mask = (zdarzenia['czas'] >= start) & (zdarzenia['czas'] < end)
suma = zdarzenia.loc[mask, 'kwota'].sum()
if suma > 0:
print(f" [{start.strftime('%H:%M')}–{end.strftime('%H:%M')}) suma = {suma:.2f}")
```
---
## Podsumowanie
Na tym wykładzie poznaliśmy dwie kluczowe architektury (Lambda i Kappa) oraz fundamentalne pojęcia przetwarzania strumieniowego: czas zdarzenia, czas przetwarzania, watermarking i okna czasowe. To pojęcia, które będą towarzyszyć nam na laboratoriach podczas pracy z Apache Kafka i Spark Structured Streaming.
::: {.callout-note appearance="simple"}
## {{< fa forward >}} Na następnym wykładzie
Uczenie maszynowe w trybie wsadowym i przyrostowym (online learning), Stochastic Gradient Descent, detekcja anomalii.
:::
::: {.callout-tip appearance="simple"}
## {{< fa brain >}} Do przemyślenia
Twój klient chce dashboard sprzedaży aktualizowany co 30 sekund. Jaką architekturę (Lambda/Kappa) byś zaproponował? Jaki typ okna czasowego zastosowałbyś?
:::