# Remove warnings
import warnings
warnings.filterwarnings('ignore')Structured data
Data as variables
# variables
customer1_age = 38
customer1_height = 178
customer1_loan = 34.23
customer1_name = 'Zajac'Why don’t we use variables for data analysis?
In Python, regardless of the type of data being analyzed and processed, we can collect data and represent it as a form of list.
# python lists - what we can put on list ?
customer = []
print(customer)# different types in one object
type(customer)Why lists aren’t the best place to store data?
Let’s take two numerical lists.”
# two numerical lists
a = [1,2,3]
b = [4,5,6]Typical operations on lists in data analysis
# add lists
print(f"a+b: {a+b}")
# we can use .format also
print("a+b: {}".format(a+b))# multiplication
try:
print(a*b)
except TypeError:
print("no-defined operation")import numpy as np
aa = np.array(a)
bb = np.array(b)
print(aa,bb)print(f"aa+bb: {aa+bb}")
# add - working
try:
print("="*50)
print(aa*bb)
print("aa*bb - is this correct ?")
print(np.dot(aa,bb))
print("np.dot - is this correct ?")
except TypeError:
print("no-defined operation")
# multiplication# array properties
x = np.array(range(4))
print(x)
x.shapeA = np.array([range(4),range(4)])
# transposition row i -> column j, column j -> row i
A.T# 0-dim object
scalar = np.array(5)
print(f"scalar object dim: {scalar.ndim}")
# 1-dim object
vector_1d = np.array([3, 5, 7])
print(f"vector object dim: {vector_1d.ndim}")
# 2 rows for 3 features
matrix_2d = np.array([[1,2,3],[3,4,5]])
print(f"matrix object dim: {matrix_2d.ndim}")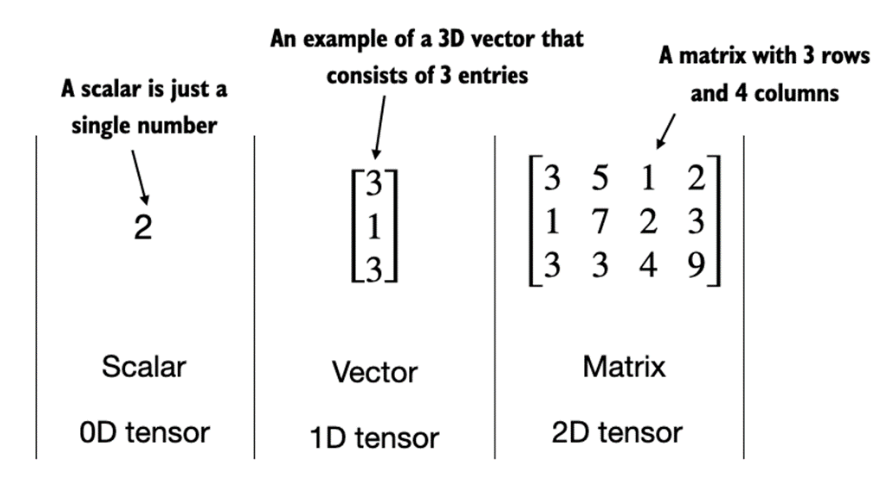
PyTorch
PyTorch is an open-source Python-based deep learning library. PyTorch has been the most widely used deep learning library for research since 2019 by a wide margin. In short, for many practitioners and researchers, PyTorch offers just the right balance between usability and features.
PyTorch is a tensor library that extends the concept of array-oriented programming library NumPy with the additional feature of accelerated computation on GPUs, thus providing a seamless switch between CPUs and GPUs.
PyTorch is an automatic differentiation engine, also known as autograd, which enables the automatic computation of gradients for tensor operations, simplifying backpropagation and model optimization.
PyTorch is a deep learning library, meaning that it offers modular, flexible, and efficient building blocks (including pre-trained models, loss functions, and optimizers) for designing and training a wide range of deep learning models, catering to both researchers and developers.
import torchtorch.cuda.is_available()tensor0d = torch.tensor(1)
tensor1d = torch.tensor([1, 2, 3])
tensor2d = torch.tensor([[1, 2, 2], [3, 4, 5]])
tensor3d = torch.tensor([[[1, 2], [3, 4]], [[5, 6], [7, 8]]])print(tensor1d.dtype)torch.tensor([1.0, 2.0, 3.0]).dtypetensor2dtensor2d.shapeprint(tensor2d.reshape(3, 2))print(tensor2d.T)print(tensor2d.matmul(tensor2d.T))print(tensor2d @ tensor2d.T)more info on pytorch
Data Modeling
Let’s take one variable (xs) and one target variable (ys - target).
xs = np.array([-1,0,1,2,3,4])
ys = np.array([-3,-1,1,3,5,7])What kind of model we can use?
# Regresja liniowa
import numpy as np
from sklearn.linear_model import LinearRegression
xs = np.array([-1,0,1,2,3,4])
# a raczej
xs = xs.reshape(-1, 1)
ys = np.array([-3, -1, 1, 3, 5, 7])
reg = LinearRegression()
model = reg.fit(xs,ys)
print(f"solution: x1={model.coef_[0]}, x0={reg.intercept_}")
model.predict(np.array([[1],[5]]))The simple code fully accomplishes our task of finding a linear regression model.
What can we use such a generated model for?
To make use of it, we need to export it to a file.
# save model
import pickle
with open('model.pkl', "wb") as picklefile:
pickle.dump(model, picklefile)Now we can import it (for example, on GitHub) and utilize it in other projects.
# load model
with open('model.pkl',"rb") as picklefile:
mreg = pickle.load(picklefile)But !!! remember about Python Env
mreg.predict(xs)Neural Networks
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Denseimport tensorflow as tfWe can also look at this problem from a different perspective. Neural networks are also capable of solving regression problems
layer_0 = Dense(units=1, input_shape=[1])
model = Sequential([layer_0])
# compiling and fits
model.compile(optimizer='sgd', loss='mean_squared_error')
model.fit(xs, ys, epochs=10)print(f"{layer_0.get_weights()}")Other ways of acquiring data
- Ready-made sources in Python libraries.
- Data from external files (e.g., CSV, JSON, TXT) from a local disk or the internet.
- Data from databases (e.g., MySQL, PostgreSQL, MongoDB).
- Data generated artificially for a chosen modeling problem.
- Data streams.
from sklearn.datasets import load_iris
iris = load_iris()# find all keys
iris.keys()# print description
print(iris.DESCR)import pandas as pd
import numpy as np
# create DataFrame
df = pd.DataFrame(data= np.c_[iris['data'], iris['target']],
columns= iris['feature_names'] + ['target'])# show last
df.tail(10)# show info about NaN values and a type of each column.
df.info()# statistics
df.describe()# new features
df['species'] = pd.Categorical.from_codes(iris.target, iris.target_names)# remove features (columns)
df = df.drop(columns=['target'])
# filtering first 100 rows and 4'th columnimport seaborn as sns
import matplotlib.pyplot as plt
sns.set(style="whitegrid", palette="husl")
iris_melt = pd.melt(df, "species", var_name="measurement")
f, ax = plt.subplots(1, figsize=(15,9))
sns.stripplot(x="measurement", y="value", hue="species", data=iris_melt, jitter=True, edgecolor="white", ax=ax)X = df.iloc[:100,[0,2]].values
y = df.iloc[0:100,4].valuesy = np.where(y == 'setosa',-1,1)plt.scatter(X[:50,0],X[:50,1],color='red', marker='o',label='setosa')
plt.scatter(X[50:100,0],X[50:100,1],color='blue', marker='x',label='versicolor')
plt.xlabel('sepal length (cm)')
plt.ylabel('petal length (cm)')
plt.legend(loc='upper left')
plt.show()For this type of linearly separable data, use logistic regression model or neural network.
from sklearn.linear_model import Perceptron
per_clf = Perceptron()
per_clf.fit(X,y)
y_pred = per_clf.predict([[2, 0.5],[4,5.5]])
y_predData Storage and Connection to a Simple SQL Database
IRIS_PATH = "https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data"
col_names = ["sepal_length", "sepal_width", "petal_length", "petal_width", "class"]
df = pd.read_csv(IRIS_PATH, names=col_names)# save to sqlite
import sqlite3
# generate database
conn = sqlite3.connect("iris.db")
# pandas to_sql
try:
df.to_sql("iris", conn, index=False)
except:
print("tabela już istnieje")# sql to pandas
result = pd.read_sql("SELECT * FROM iris WHERE sepal_length > 5", conn)result.head(3)# Artificial data
from sklearn import datasets
X, y = datasets.make_classification(n_samples=10**4,
n_features=20, n_informative=2, n_redundant=2)
from sklearn.ensemble import RandomForestClassifier
# train test split by heand
train_samples = 7000 # 70%
X_train = X[:train_samples]
X_test = X[train_samples:]
y_train = y[:train_samples]
y_test = y[train_samples:]
rfc = RandomForestClassifier()
rfc.fit(X_train, y_train)rfc.predict(X_train[0].reshape(1, -1))ZADANIA
- Load data from the
train.csvfile and put it into the panda’s data frame
## YOUR CODE HERE
df = - Show number of row and number of columns
## YOUR CODE HEREPerform missing data handling:
- Option 1 - remove rows containing missing data (
dropna()) - Option 2 - remove columns containing missing data (
drop()) - Option 3 - perform imputation using mean values (
fillna())
Which columns did you choose for each option and why?
## YOUR CODE HERE- Using the
nunique()method, remove columns that are not suitable for modeling.
## YOUR CODE HERE- Convert categorical variables using LabelEncoder into numerical form.
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
## YOUR CODE HERE- Utilize
MinMaxScalerto transform floating-point data to a common scale
from sklearn.preprocessing import MinMaxScaler
## YOUR CODE HERE- Split the data into training set (80%) and test set (20%)
from sklearn.model_selection import train_test_split
## YOUR CODE HERE
X_train, X_test, y_train, y_test = train_test_split(...., random_state=44)- Using mapping, you can classify each passenger. The
run()function requires providing a classifier for a single case.- Write a classifier that assigns a value of 0 or 1 randomly (you can use the
random.randint(0,1)function). - Execute the
evaluate()function and check how well the random classifier performs.”
- Write a classifier that assigns a value of 0 or 1 randomly (you can use the
classify = ...def run(f_classify, x):
return list(map(f_classify, x))
def evaluate(predictions, actual):
correct = list(filter(
lambda item: item[0] == item[1],
list(zip(predictions, actual))
))
return f"{len(correct)} correct answers from {len(actual)}. Accuracy ({len(correct)/len(actual)*100:.0f}%)"evaluate(run(classify, X_train.values), y_train.values)