From files to Data Mash
In recent times, a new way of handling data called stream processing has become important for companies big and small.
It’s like a supercharged version of how we used to work with data.
This new method is really good at solving the problems that old-fashioned data systems had trouble with, especially things like:
- analyzing data,
- moving it around (ETL, ELT),
- handling transactions,
- building software,
- and finding new business ideas.
Stream processing offers several advantages over traditional batch processing methodologies:
Real-time data processing: Unlike batch processing, which deals with data in discrete chunks, stream processing allows for real-time or near-real-time data processing. This is crucial for applications that require immediate insights from their data.
Scalability: Stream processing systems are designed to handle large volumes of data. They can scale horizontally to accommodate data growth, making them suitable for big data applications.
Fault tolerance: Many stream processing systems are designed to be fault-tolerant. This ensures that data processing can continue uninterrupted, even if a part of the system fails.
Integration with other systems: Stream processing systems can often integrate with various data sources and sinks, making them versatile for different data pipelines. This makes it easier to build complex data processing workflows that involve multiple data sources and sinks.
This lecture aims to explain the growing excitement around stream processing and its transformative impact on data-driven application development.
Before we dive into stream processing, let’s first understand traditional data application architectures and their limitations.
In the past, data applications have mostly used batch processing. This means data is processed in separate chunks at specific times. Think of it like baking cookies - you can only bake as many as fit on the tray at one time.
Batch processing works well in some cases, but it has problems when it comes to real-time data processing.
Imagine you’re trying to track the score of a live football game. If you’re using batch processing, you might only get updates at half-time and at the end of the game. This is because batch processing can cause delays, known as latency issues.
Batch processing also has trouble scaling, which means it can’t always handle large amounts of data efficiently. It’s like trying to bake cookies for a whole city with just one oven!
Moreover, batch processing is not very flexible. If the data changes or something unexpected happens, batch processing can’t adapt quickly. This can slow down businesses and prevent them from innovating.
In the next part of the lecture, we’ll discuss how stream processing can help overcome these limitations.
Data
When you think of data, you may think of piles of bytes sitting in data warehouses, in rational databases, or on distributed filesystems. Systems like these have trained us to think of data in its resting state. When you need to process it, you run some query or job against the pile of bytes.
The advancement of information technology has revolutionized the way we access and utilize data. With the availability of vast amounts of both structured and unstructured data, new opportunities have emerged for scientific and business challenges.
Data plays a crucial role in the creation, collection, storage, and processing of information on an unprecedented scale. This has led to the development of numerous tools and technologies that enable us to harness the power of data.
Thanks to open-source software and the computing power of home computers, we can now tackle complex problems and explore new frontiers in various domains. The possibilities are endless as we continue to push the boundaries of data-driven innovation.
The new era of business and scientific challenges brings forth a multitude of opportunities:
- Intelligent advertising for thousands of products, targeting millions of customers.
- Processing of data related to genes, RNA, or proteins, such as genus.
- Intelligent detection of fraudulent activities among hundreds of billions of credit card transactions.
- Stock market simulations based on thousands of financial instruments.
- …
As we enter the data age, we face not only the challenge of handling large quantities of data but also the need for faster data processing.
Machine learning algorithms rely on structured data in tabular form. This data is organized into columns representing characteristics that describe each observation or row. For example, these characteristics could include sex, height, or the number of cars owned. These features are used to predict whether a customer will repay a loan or not. This prediction is also included as a feature. By utilizing tables of features created in this manner, we can employ algorithms like XGBoost or logistic regression to determine the optimal combination of variables that influence the probability of a good or bad customer.
Unstructured data refers to data that does not have a predefined structure or format, such as sound, images, and text. Unlike structured data, which is organized in a tabular form with columns and rows, unstructured data lacks a consistent organization.
When processing unstructured data, it is often converted into a vector form to enable analysis and extraction of meaningful insights. However, individual elements like letters, frequencies, or pixels do not convey specific information on their own. They need to be transformed and analyzed collectively to derive valuable features and patterns.
Understanding the distinction between structured and unstructured data is crucial for effective data processing and analysis.
Give an example of structured and unstructured data. Load sample data in jupyter notebook.
Knows the types of structured and unstructured data (K2A_W02, K2A_W04, O2_W04, O2_W07)
Data sources
The three largest data generators are:
Social data: This includes texts (tweets, social network posts, comments), photos, and videos. Social data is valuable for consumer behavior analysis and sentiment analysis in marketing.
Sensor and log data: These are generated by various devices and users, such as IoT devices and website logs. Sensor and log data play a crucial role in IoT technology and are widely used in data processing and business applications.
Transaction data: This type of data is generated from online and offline transactions. Transaction data is essential for performing transactions and conducting comprehensive analytics across various domains.
Actual data generation process
The data generated in reality is a continuous stream produced by various systems and devices. For example, your phone alone generates a significant amount of data every day. This continuous generation of data is not limited to a specific time frame.
Batch processing, which involves dividing data into chunks based on a specified time interval, is one approach to processing data. However, this approach may not always be suitable, especially when dealing with real-time data streams.
To handle the continuous flow of data from different sources, various systems have been designed, including data warehouses, IoT device monitoring systems, transaction systems, website analytics systems, internet advertising platforms, social media platforms, and operating systems.
These systems play a crucial role in processing and analyzing the data stream, enabling organizations to gain valuable insights and make informed decisions.
A company is an organization that works and responds to a constant stream of data.
In traditional data processing, the input to the data source (and also the output of the evaluation) is typically a file. This file is written once and can be referenced by multiple functions or tasks.
On the other hand, in stream processing, data flows through a continuous stream of changes. This stream is generated by a source, often referred to as the “manufacturer”, “sender”, or “supplier”. The stream can be consumed by multiple recipients, known as “consumers”. The events in the stream are organized into topics.
Topics serve as a way to group related events together, allowing for efficient processing and analysis of the streaming data.
not to Big Data
,,Big Data is like teenage sex: everyone talks about it, nobody really knows how to do it, everyone thinks everyone else is doing it, so every one claims they are doing it.’’ — Dan Ariely, Professor of Psychology and Behavioral Economics, Duke University
one, two, … four V
Volume - The amount of data being generated worldwide is increasing rapidly. Students can benefit from understanding how to handle and analyze large volumes of data efficiently.
Velocity - Data is being produced and transferred at a high speed. Students need to learn how to process and analyze data in real-time to keep up with the fast-paced nature of data streams.
Variety - Data comes in various forms, including text, images, videos, and IoT data. Students should be familiar with different data types and know how to work with them effectively.
Veracity - Students need to understand the importance of data quality and reliability. They should learn how to evaluate the accuracy and completeness of data to make informed decisions based on reliable information.
Value - Students should recognize the value that data holds and how it can be used to gain insights and make informed decisions. Understanding the potential benefits and costs associated with data analysis is crucial for students in various fields of study.
The purpose of calculations is not numbers, but understanding them R.W. Hamming 1962.
Data and data processing have been integral to businesses for many decades. As time has passed, the collection and utilization of data have steadily increased, leading companies to develop robust infrastructures to manage and process this data effectively.
Data processing models
Traditional Data Processing Model
In the traditional data processing model, businesses typically implement two types of data processing:
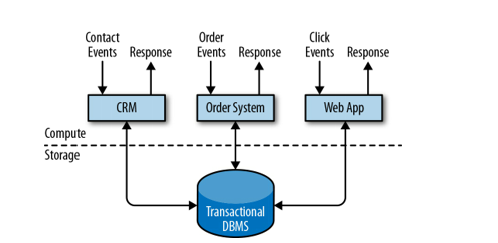
Online Transaction Processing (OLTP): This model is suitable for ongoing services such as
customer service,order registration, orsales. It involves applications that interact with external services or human users and continuously process incoming events. When an event is processed, the application reads or updates its state by running transactions against a remote database system. This model provides effective solutions for data storage, transactional data recovery, data access optimization, concurrency management, and event processing.Database Query Model: Most of the data is stored in databases or data warehouses, and access to the data is implemented through queries via applications. This model focuses on the method of using and implementing the database access process. The two most commonly used implementations are:
Relational Database Model: This model organizes data into tables with predefined relationships between them. It uses Structured Query Language (SQL) to perform operations such as querying, inserting, updating, and deleting data.
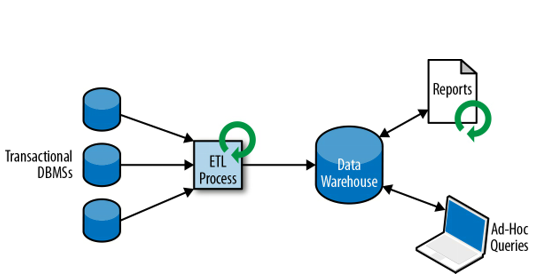
Data Warehouse Model: This model is designed for analytical processing and decision-making. It involves extracting, transforming, and loading data from various sources into a central repository, known as a data warehouse. The data in the warehouse is organized in a way that facilitates complex queries and analysis.
Understanding these traditional data processing models is essential for businesses to effectively manage and process their data.
This model offers effective solutions for:
- Efficient and secure data storage
- Transactional data recovery in case of failures
- Optimization of data access
- Concurrency management
- Event processing, involving reading and writing data
In addition to the benefits, the new data processing model and data warehouse database are particularly useful in scenarios involving:
- Aggregation of data from multiple systems, such as consolidating data from various stores or branches.
- Supporting data analysis by providing a centralized repository for performing complex queries and analysis.
- Generating data reports and summaries for business intelligence purposes.
- Optimizing complex queries to improve performance and efficiency.
- Supporting informed business decisions by providing reliable and up-to-date data.
These capabilities make the new data processing model and data warehouse database an ideal choice for organizations that require robust data management and analysis capabilities.
Research on such issues has led to the formulation of a new data processing model and a new type of database (Data warehouse).
This application design can cause problems when applications need to evolve or scale. Since multiple applications might work on the same data representation or share the same infrastructure, changing the schema of a table or scaling a database system requires careful planning and a lot of effort. Currently, many running applications (even in one area) are implemented as microservices, i.e. small and independent applications (LINUX programming philosophy - do little but right). Because microservices are strictly decoupled from each other and only communicate over well-defined interfaces, each microservice can be implemented with a different technology stack including a programming language, libraries and data stores.
This model provides effective solutions for:
- effective and safe data storage,
- transactional data recovery after a failure,
- data access optimization,
- concurrency management,
- event processing -> read -> write
And what if we are dealing with:
- aggregation of data from many systems (e.g. for many stores),
- supporting data analysis,
- data reporting and summaries,
- optimization of complex queries,
- supporting business decisions.
Research on such issues has led to the formulation of a new data processing model and a new type of database (Data warehouse).
This application design can cause problems when applications need to evolve or scale. Since multiple applications might work on the same data representation or share the same infrastructure, changing the schema of a table or scaling a database system requires careful planning and a lot of effort. Currently, many running applications (even in one area) are implemented as microservices, i.e. small and independent applications (LINUX programming philosophy - do little but right). Because microservices are strictly decoupled from each other and only communicate over well-defined interfaces, each microservice can be implemented with a different technology stack including a programming language, libraries and data stores.
Both are performed in batch mode. Today they are strictly made using Hadoop technology.