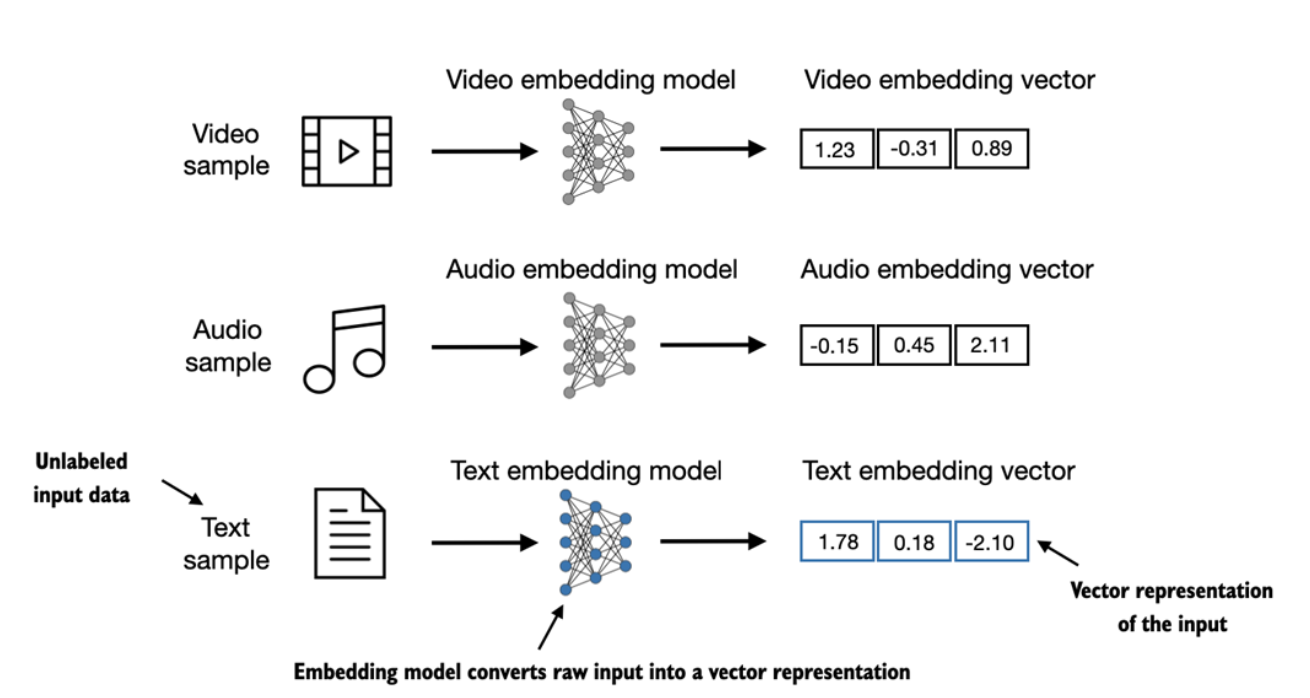
{'started': 8515,
'watching': 9725,
'series': 7957,
'cable': 1320,
'idea': 4488,
'hate': 4191,
'character': 1544,
'hold': 4339,
'beautifully': 892,
'developed': 2574,
'understand': 9375,
'react': 7196,
'frustration': 3737,
'fear': 3439,
'greed': 4020,
'temptation': 8974,
'way': 9736,
'viewer': 9574,
'experiencing': 3280,
'christopher': 1656,
'learning': 5199,
'br': 1151,
'abuse': 188,
'physically': 6608,
'emotionally': 3046,
'just': 4963,
'read': 7199,
'newspaper': 6088,
'women': 9880,
'tolerate': 9134,
'behavior': 915,
'dream': 2831,
'house': 4418,
'endless': 3074,
'supply': 8779,
'expensive': 3276,
'things': 9036,
'sure': 8791,
'loving': 5426,
'faithful': 3371,
'husband': 4465,
'maybe': 5640,
'watch': 9719,
'doesn': 2754,
'matter': 5630,
'times': 9104,
'episode': 3140,
'missed': 5813,
'episodes': 3141,
'sequence': 7950,
'season': 7869,
'late': 5151,
'night': 6101,
'commercials': 1874,
'language': 5133,
'reruns': 7427,
'movie': 5938,
'network': 6077,
've': 9529,
'totally': 9171,
'spoiled': 8437,
'love': 5420,
'neck': 6044,
'favorite': 3431,
'johnny': 4906,
'boy': 1144,
'entered': 3112,
'family': 3386,
'sign': 8134,
'life': 5270,
'ends': 3076,
'collected': 1816,
'dvd': 2910,
'collection': 1818,
'steve': 8566,
'biko': 984,
'black': 1014,
'tried': 9269,
'resist': 7440,
'white': 9800,
'minority': 5793,
'south': 8365,
'africa': 322,
'gandhi': 3787,
'british': 1209,
'empire': 3054,
'india': 4604,
'richard': 7523,
'attenborough': 701,
'film': 3509,
'freedom': 3707,
'donald': 2773,
'woods': 9894,
'liberal': 5260,
'editor': 2967,
'trying': 9302,
'tell': 8966,
'story': 8605,
'jarring': 4858,
'point': 6709,
'view': 9572,
'switch': 8855,
'dies': 2609,
'prison': 6908,
'hands': 4136,
'african': 323,
'police': 6725,
'played': 6677,
'kevin': 5007,
'kline': 5057,
'choose': 1632,
'right': 7544,
'thing': 9035,
'flee': 3575,
'country': 2133,
'books': 1102,
'allow': 405,
'wife': 9816,
'penelope': 6526,
'pressure': 6873,
'forgetting': 3650,
'case': 1443,
'vain': 9499,
'begins': 908,
'changing': 1535,
'friendship': 3723,
'standard': 8495,
'numbers': 6182,
'escape': 3162,
'border': 1109,
'yarn': 9958,
'death': 2390,
'oscar': 6320,
'nominated': 6124,
'denzel': 2497,
'washington': 9713,
'good': 3942,
'fourth': 3675,
'wrong': 9944,
'tries': 9271,
'depict': 2505,
'struggles': 8653,
'focusing': 3610,
'trials': 9261,
'half': 4117,
'served': 7963,
'topic': 9155,
'better': 965,
'rise': 7561,
'instead': 4695,
'beginning': 907,
'actor': 241,
'leading': 5190,
'role': 7609,
'hour': 4416,
'wasn': 9714,
'exactly': 3220,
'big': 975,
'box': 1140,
'office': 6244,
'tremendous': 9255,
'flop': 3594,
'politics': 6736,
'aside': 639,
'entertains': 3121,
'sends': 7922,
'message': 5722,
'albeit': 372,
'pg': 6580,
'fashion': 3412,
'stars': 8512,
'short': 8087,
'comment': 1866,
'flick': 3583,
'pick': 6613,
'chances': 1529,
'going': 3930,
'positively': 6779,
'surprised': 8801,
'diversity': 2732,
'elements': 3010,
'superbly': 8768,
'explored': 3304,
'criminal': 2209,
'thriller': 9066,
'claiming': 1697,
'pushing': 7062,
'room': 7630,
'possible': 6788,
'wont': 9890,
'push': 7059,
'nerves': 6071,
'edge': 2957,
'thumbs': 9081,
'horror': 4403,
'fan': 3388,
'certain': 1509,
'marketing': 5572,
'used': 9480,
'sell': 7910,
'movies': 5940,
'especially': 3166,
'really': 7222,
'bad': 789,
'ones': 6268,
'wouldn': 9922,
'assumed': 667,
'ripping': 7559,
'cannibal': 1365,
'zombi': 9993,
'jungle': 4957,
'holocaust': 4352,
'unfortunately': 9405,
'completely': 1916,
'hardcore': 4160,
'realized': 7219,
'saw': 7777,
'odd': 6229,
'actual': 246,
'minor': 5792,
'warning': 9701,
'notice': 6156,
'daring': 2344,
'catch': 1461,
'group': 4057,
'scientists': 7822,
'pretty': 6880,
'led': 5207,
'sea': 7858,
'captain': 1383,
'penchant': 6525,
'beach': 876,
'search': 7864,
'mutated': 5982,
'native': 6021,
'killing': 5029,
'villagers': 9586,
'nuclear': 6178,
'bomb': 1084,
'supposedly': 8788,
'island': 4814,
'radiation': 7113,
'turned': 9315,
'man': 5521,
'rapist': 7170,
'killer': 5027,
'writer': 9939,
'george': 3845,
'succeeds': 8717,
'keeping': 4994,
'clothes': 1767,
'sex': 7984,
'scenes': 7802,
'whacked': 9787,
'walk': 9661,
'nude': 6179,
'strange': 8613,
'asks': 643,
'rape': 7164,
'turns': 9318,
'chicks': 1610,
'slapping': 8222,
'naturally': 6024,
'scene': 7800,
'chick': 1608,
'toss': 9168,
'finger': 3530,
'know': 5071,
'rest': 7458,
'insane': 4667,
'oh': 6251,
'kidding': 5017,
'ton': 9140,
'like': 5287,
'pays': 6507,
'guys': 4095,
'tag': 8887,
'team': 8940,
'taking': 8894,
'use': 9479,
'cuts': 2293,
'refuses': 7296,
'advances': 295,
'starts': 8519,
'crying': 2254,
'gentleman': 3839,
'reluctantly': 7349,
'lets': 5248,
'pleasure': 6688,
'crew': 2204,
'members': 5690,
'honestly': 4368,
'waiting': 9655,
'pizza': 6649,
'guy': 4094,
'ask': 640,
'pay': 6503,
'happens': 4152,
'conduct': 1953,
'research': 7431,
'wait': 9653,
'thought': 9050,
'zombie': 9994,
'enter': 3111,
'mark': 5568,
'time': 9101,
'plenty': 6690,
'hitting': 4330,
'fast': 3416,
'forward': 3670,
'splatter': 8430,
'porn': 6756,
'don': 2772,
'think': 9037,
'does': 2753,
'justice': 4964,
'guess': 4072,
'woman': 9879,
'talking': 8905,
'say': 7779,
'plot': 6694,
'hairy': 4114,
'funny': 3759,
'worked': 9900,
'decent': 2404,
'atomic': 687,
'bombing': 1086,
'bitter': 1011,
'shakes': 8006,
'head': 4213,
'walks': 9666,
'away': 758,
'couple': 2138,
'makes': 5510,
'wonder': 9882,
'disgusted': 2693,
'feel': 3454,
'sound': 8355,
'quality': 7073,
'guessed': 4073,
'production': 6929,
'shot': 8092,
'including': 4587,
'erotic': 3157,
'nights': 6106,
'living': 5344,
'dead': 2377,
'sports': 8450,
'cast': 1453,
'said': 7716,
'wanted': 9685,
'vacation': 9495,
'paycheck': 6504,
'suddenly': 8728,
'weird': 9767,
'speaking': 8388,
'italian': 4824,
'recorded': 7255,
'english': 3092,
'dialogue': 2591,
'people': 6532,
'clearly': 1724,
'hear': 4223,
'background': 781,
'yes': 9970,
'wonderful': 9884,
'slightly': 8248,
'amusing': 454,
'score': 7827,
'couldn': 2124,
'save': 7772,
'sfx': 7992,
'minimal': 5785,
'best': 959,
'consisted': 2006,
'blood': 1050,
'violent': 9596,
'bright': 1199,
'label': 5099,
'cover': 2150,
'ploy': 6698,
'presented': 6865,
'widescreen': 9810,
'85': 153,
'aspect': 645,
'ratio': 7181,
'watched': 9721,
'region': 7304,
'rated': 7176,
'version': 9549,
'running': 7683,
'released': 7334,
'2005': 104,
'exploitation': 3298,
'digital': 2623,
'apparently': 538,
'doubt': 2790,
'different': 2616,
'shouldn': 8097,
'25': 116,
'00': 0,
'copy': 2094,
'recommend': 7250,
'pretend': 6876,
'exist': 3256,
'quote': 7098,
'civilians': 1691,
'luck': 5441,
'monsters': 5879,
'extras': 3331,
'original': 6311,
'trailer': 9204,
'shots': 8094,
'kills': 5032,
'make': 5507,
'look': 5387,
'interesting': 4733,
'trailers': 9205,
'ss': 8467,
'hell': 4251,
'camp': 1346,
'informative': 4642,
'interview': 4750,
'line': 5308,
'lame': 5119,
'porno': 6757,
'weaker': 9741,
'real': 7207,
'rating': 7179,
'10': 3,
'molly': 5856,
'www': 9954,
'com': 1836,
'robert': 7588,
'cummings': 2268,
'day': 2371,
'jean': 4866,
'star': 8503,
'beautiful': 891,
'1940': 31,
'starring': 8511,
'billie': 986,
'burke': 1282,
'15': 12,
'minutes': 5797,
'looks': 5390,
'playboy': 6676,
'desire': 2541,
'sisters': 8181,
'katherine': 4982,
'helen': 4248,
'likes': 5291,
'fix': 3554,
'cars': 1435,
'blonde': 1048,
'social': 8302,
'butterfly': 1307,
'arrives': 612,
'town': 9182,
'believing': 930,
'party': 6464,
'decides': 2409,
'attend': 702,
'given': 3892,
'friend': 3720,
'mother': 5916,
'dress': 2837,
'connect': 1976,
'sees': 7899,
'dinner': 2634,
'left': 5210,
'club': 1772,
'terribly': 8995,
'drunk': 2869,
'ride': 7533,
'car': 1391,
'won': 9881,
'let': 5245,
'drive': 2851,
'walking': 9665,
'awhile': 764,
'breaking': 1175,
'shoe': 8077,
'gets': 3859,
'drives': 2856,
'passes': 6472,
'takes': 8893,
'wheel': 9791,
'accidentally': 206,
'remember': 7364,
'blame': 1021,
'sister': 8180,
'shoes': 8078,
'plus': 6701,
'manner': 5540,
'realize': 7218,
'isn': 4816,
'telling': 8967,
'truth': 9298,
'convicted': 2071,
'goes': 3929,
'marries': 5580,
'leaves': 5204,
'america': 439,
'list': 5325,
'playing': 6681,
'taylor': 8932,
'mgm': 5737,
'handsome': 4137,
'amiable': 442,
'dazzling': 2375,
'actress': 243,
'constantly': 2014,
'didn': 2603,
'great': 4013,
'face': 3343,
'voice': 9626,
'determined': 2569,
'sympathetic': 8871,
'lovely': 5422,
'lousy': 5418,
'highly': 4296,
'recommended': 7252,
'little': 5337,
'gem': 3819,
'dark': 2345,
'overlooked': 6359,
'known': 5074,
'early': 2927,
'80': 151,
'deserves': 2535,
'audience': 717,
'damn': 2320,
'shame': 8013,
'seen': 7898,
'compared': 1893,
'gotten': 3965,
'bigger': 977,
'years': 9964,
'notably': 6150,
'comparisons': 1897,
'bit': 1003,
'similar': 8147,
'slipped': 8252,
'acceptance': 198,
'remake': 7358,
'breathe': 1181,
'new': 6082,
'unless': 9426,
'drained': 2816,
'remakes': 7359,
'days': 2373,
'work': 9899,
'lesser': 5240,
'films': 3516,
'awful': 761,
'ghost': 3863,
'ship': 8064,
'opening': 6275,
'falling': 3377,
'utter': 9492,
'crap': 2169,
'happen': 4148,
'fall': 3375,
'lot': 5410,
'haven': 4201,
'bring': 1204,
'course': 2143,
'got': 3961,
'eyes': 3338,
'anyways': 526,
'fans': 3392,
'cause': 1474,
'creepy': 2203,
'setting': 7972,
'fairly': 3367,
'acting': 234,
'campy': 1354,
'want': 9684,
'nudity': 6180,
'gore': 3954,
'sorry': 8347,
'nonetheless': 6128,
'solid': 8315,
'enjoy': 3099,
'grave': 4006,
'robber': 7583,
'sitting': 8188,
'cell': 1491,
'awaiting': 750,
'execution': 3251,
'visited': 9612,
'monk': 5868,
'wishing': 9860,
'words': 9897,
'horrible': 4397,
'lead': 5187,
'reluctant': 7348,
'tongue': 9144,
'drink': 2847,
'young': 9975,
'soon': 8334,
'undead': 9366,
'bump': 1275,
'york': 9974,
'filmed': 3510,
'brought': 1228,
'spirit': 8424,
'andy': 467,
'milligan': 5769,
'lurking': 5457,
'comedies': 1850,
'come': 1845,
'rate': 7175,
'dominic': 2770,
'plays': 6682,
'arthur': 619,
'blake': 1020,
'ron': 7626,
'father': 3423,
'statement': 8523,
'getting': 3860,
'involved': 4786,
'tale': 8896,
'men': 5695,
'having': 4202,
'grand': 3985,
'old': 6256,
'shows': 8109,
'equally': 3145,
'music': 5972,
'jeff': 4869,
'grace': 3972,
'excellent': 3230,
'effects': 2979,
'perfect': 6539,
'sort': 8348,
'silliness': 8143,
'deal': 2381,
'fun': 3747,
'trouble': 9288,
'throws': 9076,
'net': 6075,
'wide': 9807,
'result': 7465,
'needed': 6047,
'alien': 389,
'body': 1075,
'mix': 5830,
'theaters': 9018,
'later': 5153,
'll': 5347,
'worth': 9918,
'liked': 5289,
'script': 7851,
'changed': 1533,
'reason': 7225,
'rodney': 7603,
'dangerfield': 2334,
'jackie': 4837,
'mason': 5605,
'did': 2602,
'alot': 413,
'kept': 5004,
'flaw': 3571,
'dan': 2324,
'murray': 5968,
'carl': 1411,
'quit': 7096,
'job': 4898,
'assistant': 659,
'joined': 4909,
'military': 5764,
'warner': 9700,
'bros': 1224,
'ii': 4509,
'try': 9301,
'seeing': 7893,
'possibly': 6789,
'disappointed': 2662,
'fact': 3349,
'director': 2646,
'cube': 2260,
'comedy': 1851,
'imdb': 4531,
'spell': 8405,
'word': 9896,
'reminiscent': 7373,
'builds': 1263,
'slowly': 8258,
'gradually': 3976,
'explanation': 3291,
'mainly': 5500,
'set': 7970,
'respects': 7452,
'probably': 6915,
'commented': 1870,
'masterpiece': 5614,
'spanish': 8378,
'cinema': 1673,
'masters': 5616,
'piece': 6623,
'long': 5383,
'ago': 338,
'midnight': 5753,
'cowboy': 2158,
'les': 5236,
'du': 2872,
'realistic': 7213,
'non': 6127,
'spot': 8451,
'trainspotting': 9210,
'hard': 4159,
'place': 6650,
'humour': 4446,
'obviously': 6214,
'dramatic': 2820,
'sense': 7926,
'diamond': 2593,
'resurrection': 7470,
'neo': 6064,
'realism': 7211,
'mixed': 5831,
'ken': 4999,
'discover': 2677,
'modern': 5849,
'tv': 9320,
'classic': 1709,
'bob': 1072,
'girlfriend': 3889,
'named': 6003,
'alicia': 388,
'married': 5579,
'bud': 1247,
'owen': 6375,
'works': 9904,
'jealous': 4864,
'hanging': 4140,
'hangs': 4141,
'secretary': 7881,
'heather': 4237,
'accident': 204,
'prone': 6970,
'kind': 5035,
'lonely': 5380,
'wishes': 9859,
'friends': 3722,
'end': 3069,
'looked': 5388,
'finally': 3521,
'went': 9776,
'driving': 2857,
'wedding': 9759,
'making': 5512,
'tiny': 9110,
'stuck': 8658,
'middle': 5750,
'happened': 4149,
'poor': 6744,
'ended': 3071,
'guide': 4078,
'fox': 3676,
'twice': 9323,
'putting': 7064,
'air': 356,
'loved': 5421,
'cool': 2082,
'glasses': 3901,
'hilarious': 4298,
'miss': 5812,
'reading': 7203,
'book': 1101,
'ending': 3072,
'missing': 5817,
'sad': 7707,
'treatment': 9250,
'subject': 8692,
'quite': 7097,
'controversial': 2055,
'comments': 1872,
'distinction': 2712,
'based': 845,
'believe': 926,
'portrayed': 6768,
'basically': 850,
'sequels': 7949,
'30': 122,
'values': 9507,
'plan': 6658,
'outer': 6331,
'space': 8370,
'level': 5253,
'glen': 3902,
'glenda': 3903,
'ed': 2954,
'wood': 9892,
'religious': 7347,
'scary': 7796,
'add': 257,
'slightest': 8247,
'actually': 247,
'close': 1758,
'future': 3766,
'scarier': 7791,
'reasons': 7229,
'code': 1792,
'thief': 9033,
'explain': 3287,
'east': 2938,
'effect': 2976,
'happening': 4150,
'forget': 3647,
'stories': 8603,
'told': 9131,
'god': 3921,
'frightening': 3727,
'wild': 9818,
'rebels': 7234,
'frustrating': 3736,
'deals': 2385,
'race': 7104,
'driver': 2854,
'bikers': 982,
'called': 1331,
'satan': 7759,
'angels': 473,
'hang': 4139,
'decide': 2406,
'rob': 7581,
'bank': 818,
'cops': 2093,
'report': 7406,
'dated': 2360,
'carry': 1433,
'significantly': 8139,
'crude': 2247,
'stupid': 8679,
'band': 814,
'stage': 8477,
'performing': 6549,
'regular': 7308,
'generic': 3830,
'care': 1396,
'taken': 8891,
'filmmaker': 3512,
'logic': 5369,
'direction': 2643,
'actors': 242,
'parts': 6463,
'major': 5505,
'indifferent': 4612,
'unpredictable': 9439,
'comes': 1852,
'florida': 3595,
'ho': 4334,
'worthy': 9921,
'mystery': 5992,
'science': 7819,
'theater': 9017,
'3000': 124,
'status': 8532,
'commentary': 1868,
'characters': 1550,
'screen': 7841,
'saying': 7780,
'pack': 6390,
'low': 5428,
'expectations': 3270,
'came': 1338,
'months': 5887,
'tragedy': 9200,
'open': 6273,
'wounds': 9925,
'thank': 9012,
'bravery': 1167,
'offered': 6240,
'closure': 1765,
'consider': 1998,
'hidden': 4285,
'frontier': 3731,
'somewhat': 8326,
'small': 8265,
'met': 5727,
'counting': 2130,
'conventions': 2062,
'2001': 100,
'continue': 2036,
'impressed': 4559,
'self': 7908,
'studio': 8663,
'pictures': 6620,
'fancy': 3390,
'writers': 9940,
'walter': 9673,
'aka': 363,
'mr': 5942,
'manage': 5522,
'create': 2183,
'replacing': 7403,
'ghastly': 3861,
'experiment': 3281,
'enterprise': 3114,
'successful': 8719,
'arc': 571,
'introduction': 4765,
'trek': 9254,
'openly': 6276,
'gay': 3811,
'corey': 2098,
'introduced': 4762,
'second': 7876,
'soul': 8353,
'mate': 5622,
'meets': 5674,
'officer': 6245,
'recent': 7241,
'lines': 5312,
'spoiler': 8438,
'causing': 1477,
'change': 1532,
'conflict': 1964,
'relationship': 7325,
'uncertain': 9355,
'shown': 8108,
'chat': 1570,
'endure': 3077,
'gene': 3823,
'created': 2184,
'intention': 4723,
'flashy': 3566,
'battles': 868,
'popular': 6752,
'previous': 6886,
'stated': 8522,
'wish': 9857,
'higher': 4291,
'suffice': 8734,
'tradition': 9195,
'seven': 7978,
'generation': 3828,
'willing': 9829,
'bet': 960,
'final': 3519,
'debut': 2398,
'1958': 50,
'enjoyed': 3101,
'leave': 5203,
'sons': 8332,
'harriet': 4176,
'dick': 2599,
'van': 9510,
'lucy': 5444,
'enjoying': 3102,
'donna': 2774,
'reed': 7273,
'stone': 8590,
'intelligent': 4714,
'mannered': 5541,
'problem': 6916,
'solving': 8321,
'stay': 8533,
'home': 4356,
'mom': 5857,
'june': 4956,
'contrast': 2045,
'ms': 5944,
'dad': 2304,
'boxing': 1143,
'teaching': 8939,
'son': 8327,
'defend': 2430,
'larger': 5141,
'bully': 1271,
'mothers': 5917,
'neighborhood': 6056,
'grew': 4030,
'idealistic': 4490,
'standards': 8496,
'refreshing': 7291,
'manners': 5543,
'decision': 2411,
'today': 9124,
'accepted': 199,
'indifference': 4611,
'neighbors': 6057,
'imagine': 4528,
'mary': 5599,
'parents': 6443,
'okay': 6254,
'leaving': 5205,
'dog': 2755,
'outside': 6345,
'acceptable': 197,
'shut': 8114,
'supermarket': 8775,
'cinematography': 1678,
'highlights': 4295,
'true': 9292,
'account': 216,
'1950s': 43,
...}