undersampler = RandomUnderSampler(random_state=seed)# UWAGA: undersampling stosujemy tylko do zbioru treningowegoX_train_under, y_train_under = undersampler.fit_resample(X_train_scaled, y_train)X_test_under, y_test_under = undersampler.fit_resample(X_test_scaled, y_test)print(f"\nUndersampling completed:")print(f"Train set balanced to: {np.bincount(y_train_under)} (0 and 1 equally frequent)")print(f"Test set balanced to: {np.bincount(y_test_under)} (0 and 1 equally frequent)")Undersampling completed:Train set balanced to: [394394] (0and1 equally frequent)Test set balanced to: [9898] (0and1 equally frequent)
print("\nFinal shapes:")print(f"X_train_under: {X_train_under.shape}")print(f"y_train_under: {y_train_under.shape}")print(f"X_test_scaled: {X_test_under.shape}")print(f"y_test: {y_test_under.shape}")Final shapes:X_train_under: (788, 30)y_train_under: (788,)X_test_scaled: (196, 30)y_test: (196,)import os# === 6. Zapisanie przygotowanych zbiorów do plików CSV ===SAVE_DIR ="../../dane/przetworzone"os.makedirs(SAVE_DIR, exist_ok=True)X_train.to_csv(os.path.join(SAVE_DIR, "X_train.csv"), index=False)y_train.to_csv(os.path.join(SAVE_DIR, "y_train.csv"), index=False)# # Zbiór treningowy po undersamplingu (do trenowania modeli)X_train_under.to_csv(os.path.join(SAVE_DIR, "X_train_under.csv"), index=False)y_train_under.to_csv(os.path.join(SAVE_DIR, "y_train_under.csv"), index=False)# # Zbiór testowy (pozostaje niezbalansowany, do oceny modeli)X_test_under.to_csv(os.path.join(SAVE_DIR, "X_test_under.csv"), index=False)y_test_under.to_csv(os.path.join(SAVE_DIR, "y_test_under.csv"), index=False)
Metody selekcji zmiennych
import pandas as pdimport numpy as npfrom sklearn.linear_model import LogisticRegressionfrom sklearn.metrics import roc_auc_scorefrom sklearn.preprocessing import MinMaxScalerresults = []for column in X_train.columns:# Dane tylko z jedną zmienną feature_train = X_train[[column]] feature_test = X_test[[column]]# Skalowanie do 0–1 scaler = MinMaxScaler() feature_train_scaled = scaler.fit_transform(feature_train) feature_test_scaled = scaler.transform(feature_test)# Regresja logistyczna model = LogisticRegression() model.fit(feature_train_scaled, y_train)# Predykcja i GINI probs = model.predict_proba(feature_test_scaled)[:, 1] auc = roc_auc_score(y_test, probs) gini =2* auc -1 results.append((column, gini))results_sorted =sorted(results, key=lambda x: x[1], reverse=True)# Wyświetlenieprint("Top zmienne wg statystyki GINI (logreg 1-cechowa):\n")for name, g in results_sorted:print(f"{name:<20} GINI = {g:.4f}")# Najlepsza zmiennabest_variable = results_sorted[0][0]print(f"\n✅ Najlepsza zmienna: {best_variable} (do modelu kwantowego 1-kubitowego)")Top zmienne wg statystyki GINI (logreg 1-cechowa):V12 GINI =0.9094V14 GINI =0.9086V11 GINI =0.8802V4 GINI =0.8485V3 GINI =0.8248V10 GINI =0.8183V16 GINI =0.7020V7 GINI =0.6975V17 GINI =0.6738V9 GINI =0.6626V1 GINI =0.6323V6 GINI =0.5821V18 GINI =0.5472V5 GINI =0.4606scaled_time GINI =0.2589V23 GINI =0.1208scaled_amount GINI =0.1156V24 GINI =0.1108V22 GINI =0.0233V13 GINI =-0.0158V15 GINI =-0.0395V25 GINI =-0.0943V26 GINI =-0.0987...V21 GINI =-0.4992V2 GINI =-0.7163
Model XGB
import xgboost as xgbmodel = xgb.XGBClassifier(max_depth=1,n_estimators=1)model.fit(X_train, y_train)booster = model.get_booster()df = booster.trees_to_dataframe()# Pierwszy wiersz to pierwszy podział w pierwszym drzewiesplit_variable = df.loc[0, "Feature"]split_value = df.loc[0, "Split"]print(f"Model użył zmiennej: {split_variable}, wartość progowa: {split_value}")Model użył zmiennej: V14, wartość progowa: -3.6156354
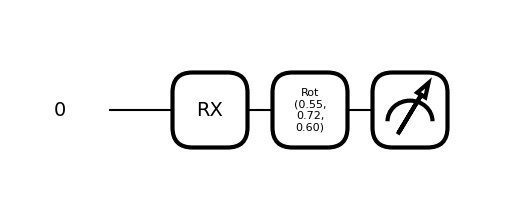
Jedno-kubitowe Modele Kwantowe
# ======================================================# 1️⃣ IMPORTY I USTAWIENIA# ======================================================import osimport pandas as pdfrom sklearn.preprocessing import MinMaxScalerimport pennylane as qmlimport pennylane.numpy as npfrom pennylane.optimize import NesterovMomentumOptimizer# Ścieżka do katalogu z przetworzonymi danymiDATA_DIR ="../data/credit/"# ======================================================# 2️⃣ WCZYTANIE DANYCH# ======================================================X_train_under = pd.read_csv(os.path.join(DATA_DIR, "X_train_under.csv"))y_train = pd.read_csv(os.path.join(DATA_DIR, "y_train_under.csv"))X_test = pd.read_csv(os.path.join(DATA_DIR, "X_test_under.csv"))y_test = pd.read_csv(os.path.join(DATA_DIR, "y_test_under.csv"))print(f"Train shape: X={X_train_under.shape}, y={y_train.shape}")print(f"Test shape: X={X_test.shape}, y={y_test.shape}")y_train = y_train *2-1y_test = y_test *2-1
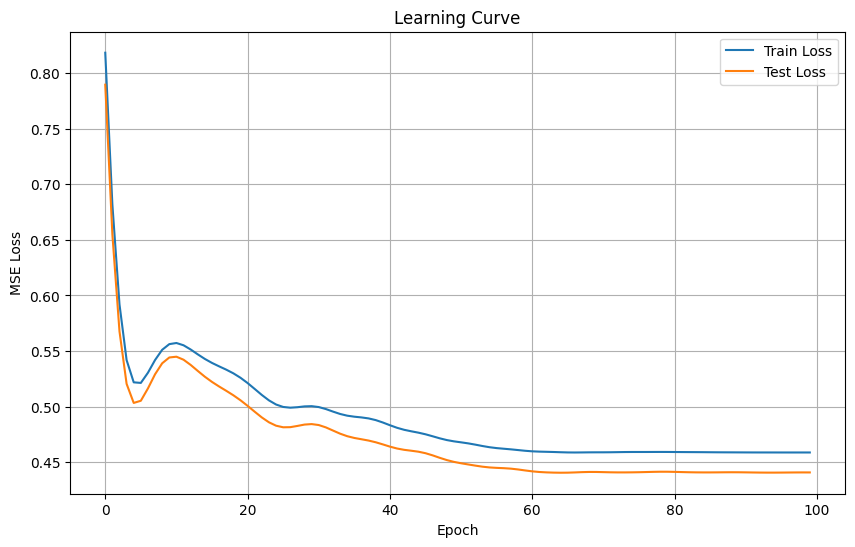
test_full_preds = [variational_classifier(weights, bias, x) for x in X_test_full_f]test_preds = [variational_classifier(weights, bias, x) for x in X_test_f]
def res(x):if x >0:return1return-1wyniki_full = [res(k) for k in qml.math.stack(test_full_preds)]wyniki = [res(k) for k in qml.math.stack(test_preds)]